Parallel computing brings exciting possibilities and tough challenges. It's like having a team of super-fast workers, but you need to coordinate them perfectly. The key is balancing the power of multiple processors with the headaches of managing them all.
From big data crunching to cutting-edge science, parallel computing opens doors. But it's not always smooth sailing. You'll face hurdles like resource sharing, communication overhead, and tricky debugging. It's a constant juggling act between speed and complexity.
Challenges in Parallel System Design
Concurrency and Resource Management
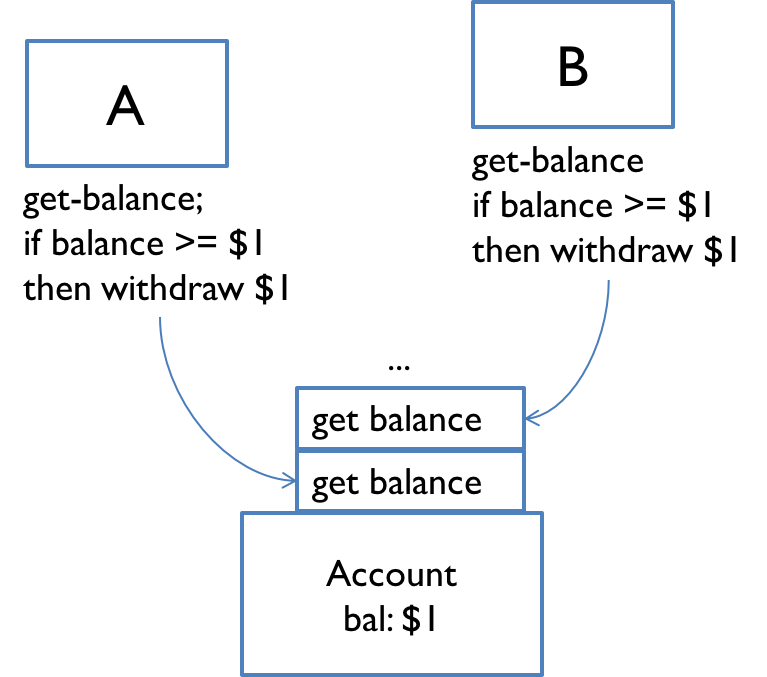
- Concurrency control and synchronization manage shared resources and ensure data consistency
- Requires mechanisms like locks, semaphores, and atomic operations
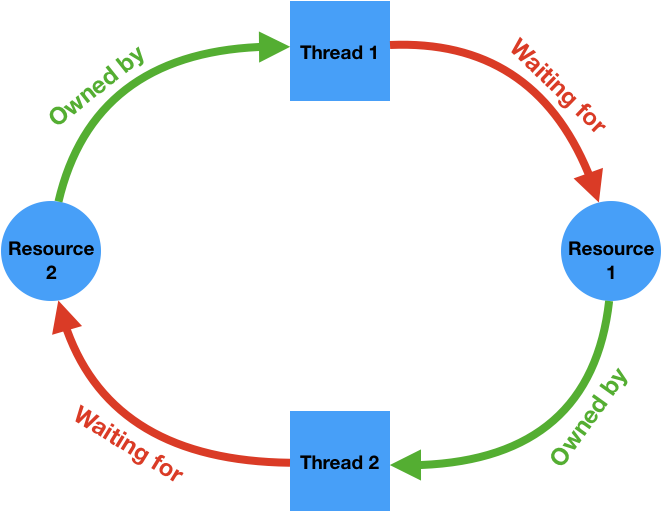
- Challenges include deadlocks, race conditions, and priority inversion
- Load balancing distributes workload across multiple processors or nodes
- Maximizes system utilization and efficiency
- Techniques include static partitioning, dynamic scheduling, and work stealing
- Communication overhead impacts parallel system performance
- Necessitates careful consideration of data transfer strategies
- Inter-process communication methods (shared memory, message passing)
- Debugging and testing parallel systems present unique complexities
- Requires specialized tools (parallel debuggers, race detectors)
- Techniques include record-and-replay debugging and statistical profiling
Hardware and Algorithmic Limitations
- Hardware limitations constrain performance gains through parallelization
- Memory bandwidth bottlenecks (limited data transfer rates)
- Cache coherence issues (maintaining consistent data across multiple caches)
- Parallel algorithm design faces unique challenges
- Not all problems can be efficiently parallelized (inherently sequential tasks)
- Some require fundamental restructuring of sequential algorithms
- Examples include graph algorithms and certain numerical methods
- Scalability challenges arise when increasing processors or problem size
- Diminishing returns due to increased communication overhead
- Load imbalance becomes more pronounced at larger scales
Scalability and Performance in Parallel Computing
Theoretical Models and Laws
- Amdahl's Law quantifies theoretical speedup in task execution latency
- Applies to fixed workload scenarios
- Formula: Where S(n) is speedup, n is number of processors, p is parallelizable portion
- Gustafson's Law addresses shortcomings of Amdahl's Law
- Focuses on speedup variation with problem size for fixed time
- Formula: Where α is the non-parallelizable portion of the program
- Strong scaling examines solution time variation with processor count
- Fixed total problem size
- Ideal strong scaling: halving time when doubling processors
- Weak scaling describes solution time variation with processor count
- Fixed problem size per processor
- Ideal weak scaling: constant time as processors and problem size increase proportionally
Performance Metrics and Phenomena
- Parallel efficiency measures processor utilization in problem-solving
- Compares useful work to communication and synchronization overhead
- Formula: where E is efficiency, S(n) is speedup, n is number of processors
- Speedup anomalies occur due to system-specific factors
- Superlinear speedup (speedup greater than number of processors)
- Causes include cache effects and reduced sequential bottlenecks
- Scalability bottlenecks arise from various sources
- Algorithmic limitations (inherently sequential portions)
- Communication overhead (increased data transfer with more processors)
- Resource contention (competition for shared memory or network bandwidth)
Opportunities for Parallel Computing
Data-Intensive Applications
- Big data analytics leverages parallel computing for massive dataset processing
- Distributed systems like Hadoop and Spark
- Applications in business intelligence, social media analysis, and scientific research
- Machine learning and AI benefit from parallelization
- Training large neural networks (distributed deep learning)
- Processing complex datasets for model training and inference
- Real-time data processing and streaming applications utilize parallel computing
- Handling high-velocity data streams efficiently
- Examples include financial trading systems and network traffic analysis
Scientific and Visual Computing
- Scientific simulations leverage parallel computing for complex problems
- Climate modeling (atmospheric and oceanic simulations)
- Molecular dynamics (protein folding, drug discovery)
- Computer vision and image processing tasks accelerated through parallelization
- Real-time object detection and recognition
- Medical image analysis and autonomous vehicle perception
- Quantum computing presents a new paradigm for parallel processing
- Potential breakthroughs in cryptography and optimization problems
- Quantum algorithms for database searching and factorization
Edge and Distributed Computing
- Edge computing and IoT devices leverage parallel processing
- Enhances local computation capabilities
- Reduces latency for time-sensitive applications
- Distributed systems enable large-scale parallel computations
- Grid computing for scientific research
- Volunteer computing projects (SETI@home, Folding@home)
Trade-offs in Parallel Computing Approaches
Architectural and Programming Model Considerations
- Shared memory vs. distributed memory architectures involve trade-offs
- Shared memory offers easier programming but limited scalability
- Distributed memory provides better scalability but increased complexity
- Fine-grained vs. coarse-grained parallelism presents performance trade-offs
- Fine-grained offers more parallelism but increases synchronization costs
- Coarse-grained reduces overhead but may limit scalability
- Parallel programming models impact development and performance
- OpenMP for shared memory systems (ease of use, limited scalability)
- MPI for distributed memory systems (high scalability, increased complexity)
- CUDA for GPU computing (high performance for suitable problems, hardware-specific)
System-Level Considerations
- Energy efficiency in parallel systems balances performance and power consumption
- Dynamic voltage and frequency scaling techniques
- Power-aware scheduling algorithms
- Fault tolerance becomes crucial as system scale increases
- Checkpoint-restart mechanisms for long-running computations
- Redundancy and replication strategies in distributed systems
- Cost-effectiveness of parallel solutions must be evaluated
- Hardware expenses (multi-core processors, networking equipment)
- Development time and expertise requirements
- Maintenance complexity and operational costs
- Parallel algorithms and data structures impact performance and scalability
- Requires analysis of problem characteristics and system architecture
- Examples include parallel sorting algorithms and concurrent data structures