Distributed system architectures form the backbone of modern computing, enabling resource sharing and collaboration across networks. This section explores the key characteristics, trade-offs, and architectural approaches that shape these systems, from centralized to decentralized models.
We'll dive into the role of middleware, which acts as a crucial intermediary layer in distributed systems. Understanding these concepts is essential for designing scalable, fault-tolerant, and efficient distributed systems that power today's interconnected digital world.
Distributed Systems: Key Characteristics
Resource Sharing and Openness
- Distributed systems comprise multiple autonomous computational entities (nodes) communicating and coordinating to achieve a common goal
- Resource sharing enables efficient utilization of computing resources across the network (hardware, software, and data)
- Openness allows system extension and modification through standardized interfaces and protocols
- Concurrency permits multiple processes to execute simultaneously across different nodes enhancing overall system performance
Scalability and Fault Tolerance
- Scalability accommodates growth in users, resources, or geographical distribution without significant performance degradation
- Fault tolerance mechanisms enable continued system functioning in the presence of failures ensuring reliability and availability
- Transparency hides the complexity of the distributed nature from users and application programmers presenting the system as a single coherent unit
- Examples of fault tolerance mechanisms include replication (data mirroring) and redundancy (backup servers)
Centralized vs Decentralized vs Hybrid Architectures
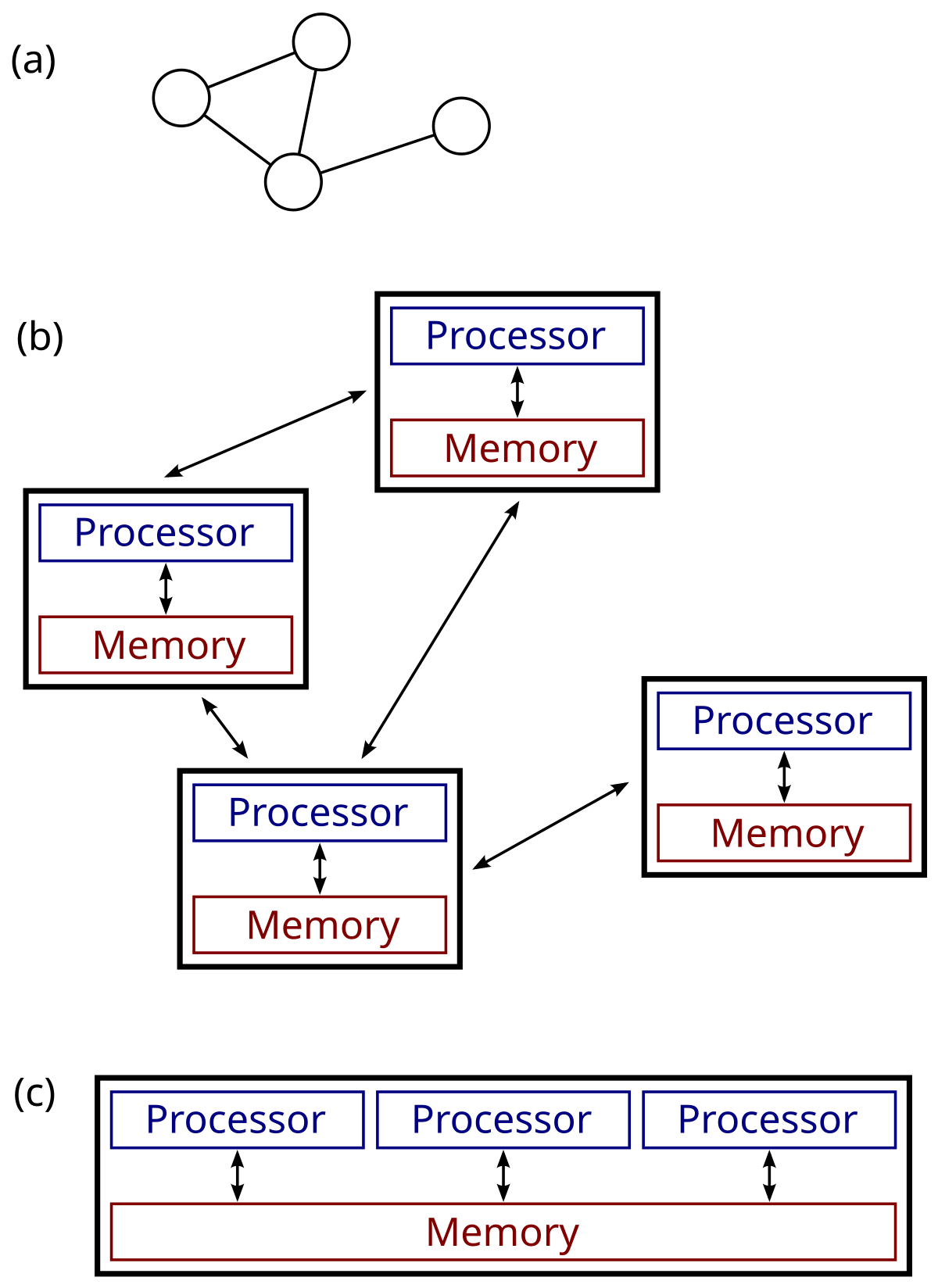
Centralized and Decentralized Systems
- Centralized architectures rely on a single central server or cluster to manage all resources and operations
- Offers simplicity but potentially creates a single point of failure
- Provides stronger consistency and easier management
- Decentralized architectures distribute control and decision-making across multiple nodes
- Enhances fault tolerance and scalability but increases complexity
- Often employ peer-to-peer (P2P) networks where nodes have equal roles and responsibilities
- Examples of centralized systems include traditional client-server models (central database server)
- Examples of decentralized systems include blockchain networks (Bitcoin) and distributed file sharing (BitTorrent)
Hybrid Architectures and Considerations
- Hybrid architectures combine elements of both centralized and decentralized approaches
- Aims to balance advantages and disadvantages of centralized and decentralized systems
- May use hierarchical structure with centralized control at higher levels and decentralized operations at lower levels
- Choice between architectures depends on factors such as:
- System requirements
- Scalability needs
- Fault tolerance requirements
- Geographical distribution of resources and users
- Examples of hybrid systems include content delivery networks (CDNs) and cloud computing platforms (AWS)
Trade-offs in Distributed Systems
Performance and Scalability
- Performance measured by metrics such as throughput, latency, and resource utilization
- Affected by network communication overhead and load balancing
- Scalability refers to system's ability to handle increased load by adding resources
- May impact performance due to increased coordination and communication requirements
- Improving scalability often involves partitioning data and services
- Complicates maintaining consistency across the system
- Examples of performance optimization techniques include caching (Redis) and load balancing (Nginx)
Fault Tolerance and Consistency
- Fault tolerance mechanisms enhance system reliability but introduce overhead and complexity
- Potentially affecting performance and scalability
- CAP theorem states impossibility of simultaneously providing consistency, availability, and partition tolerance
- Trade-offs must be made based on system requirements
- Increasing fault tolerance through replication may improve availability but negatively impact consistency
- Introduces additional network traffic
- Examples of fault tolerance strategies include primary-backup replication (MySQL replication) and sharding (MongoDB)
Middleware in Distributed Systems
Functions and Communication Paradigms
- Middleware acts as intermediary layer between distributed applications and underlying network infrastructure
- Provides abstraction and facilitates communication
- Key functions include:
- Providing uniform programming model
- Masking heterogeneity of hardware, operating systems, and network protocols
- Supports various communication paradigms:
- Remote procedure calls (RPC)
- Message-oriented middleware (MOM)
- Publish-subscribe systems
- Implements mechanisms for ensuring reliability, security, and quality of service in distributed communications
- Examples of middleware include gRPC (RPC framework) and Apache Kafka (message broker)
Types and Role in Transparency
- Common types of middleware:
- Object-oriented middleware (CORBA)
- Service-oriented middleware (web services)
- Message-oriented middleware (RabbitMQ)
- Provides services for naming, discovery, and location of resources and services within distributed system
- Plays crucial role in implementing transparency in distributed systems
- Hides complexities of distribution from application developers and users
- Examples of middleware-enabled transparency include distributed file systems (NFS) and distributed databases (Cassandra)