Distributed coordination and synchronization are crucial for maintaining consistency and coherence across multiple nodes in distributed systems. These techniques enable processes to work together effectively, avoid conflicts, and maintain data integrity. They're essential for implementing distributed algorithms and addressing challenges in distributed environments.
Coordination and synchronization face challenges like network latency, clock drift, and partial failures. Solutions include using asynchronous communication models, implementing clock synchronization algorithms, and designing fault-tolerant mechanisms. These approaches contribute to the overall reliability, scalability, and performance of distributed systems.
Coordination and Synchronization in Distributed Systems
Importance of Coordination and Synchronization
- Maintain consistency and coherence across multiple nodes in distributed systems
- Enable distributed processes to work together effectively avoiding conflicts and maintaining data integrity
- Allow efficient resource allocation and load balancing among distributed components
- Help maintain consistent global state and enable correct ordering of events across different nodes
- Essential for implementing distributed algorithms (consensus protocols, distributed transactions)
- Address challenges in distributed environments (network partitions, node failures, concurrent access to shared resources)
- Contribute to overall reliability, scalability, and performance of distributed systems
Challenges and Solutions in Distributed Coordination
- Network latency introduces delays in communication between nodes
- Solution: Use asynchronous communication models to reduce waiting times
- Clock drift causes time discrepancies across nodes
- Solution: Implement clock synchronization algorithms (Network Time Protocol)
- Partial failures require robust fault-tolerance mechanisms
- Solution: Design algorithms that can handle node failures and network partitions
- Concurrent access to shared resources leads to race conditions
- Solution: Implement distributed mutual exclusion algorithms
- Scalability issues arise as the number of nodes increases
- Solution: Adopt decentralized coordination techniques to distribute the workload
Clocks, Events, and Ordering in Distributed Environments
Logical and Physical Clocks
- Logical clocks establish partial ordering of events in distributed systems
- Lamport timestamps: Assign monotonically increasing values to events
- Vector clocks: Capture causal relationships between events across multiple processes
- Physical clocks may drift in distributed systems leading to time inconsistencies
- Clock drift rates typically range from 10^-6 to 10^-4 seconds per second
- Clock synchronization algorithms align clocks across distributed nodes
- Network Time Protocol (NTP): Hierarchical, multi-tiered architecture for time synchronization
- Precision Time Protocol (PTP): Higher accuracy for time-sensitive applications (financial trading)

Event Ordering and Causality
- Happened-before relation defines partial ordering of events based on causal relationships
- If event A happened-before event B, A could potentially influence B
- Total ordering of events challenging due to lack of single global clock and network delays
- Distributed systems often rely on partial ordering for consistency
- Causal ordering ensures messages are delivered in a causally consistent manner
- Used in distributed messaging systems (Apache Kafka)
- Total ordering crucial for maintaining consistency in distributed databases
- Implemented in distributed consensus protocols (Paxos, Raft)
Distributed Coordination Algorithms
Leader Election Algorithms
- Select coordinator node in distributed system to manage specific tasks
- Bully algorithm: Nodes with higher IDs attempt to become the leader
- Time complexity: O(n^2) in worst case, where n is number of nodes
- Ring algorithm: Nodes arranged in logical ring, election message passed around
- Message complexity: O(n) in best case, O(n^2) in worst case
Mutual Exclusion Algorithms
- Ensure only one process accesses shared resource at a time across multiple nodes
- Lamport's Distributed Mutual Exclusion algorithm uses logical clocks for request ordering
- Requires 3(n-1) messages per critical section entry, where n is number of nodes
- Token-based algorithms (Suzuki-Kasami) use unique token to grant critical section access
- Token passing reduces message overhead in low-contention scenarios
- Quorum-based algorithms (Maekawa's) use voting mechanisms for mutual exclusion
- Reduces message complexity to O(√n) per critical section entry
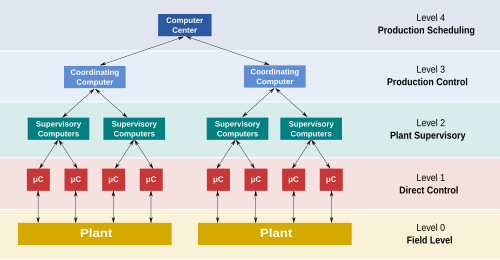
Consensus Algorithms
- Achieve agreement on single data value among distributed processes
- Paxos: Classic consensus algorithm for asynchronous systems
- Roles: Proposers, Acceptors, Learners
- Raft: Designed for understandability and practical implementation
- Leader-based approach with log replication
Centralized vs Decentralized Synchronization Techniques
Centralized Synchronization Approaches
- Offer simplicity and strong consistency in distributed systems
- Single coordinator manages synchronization for all nodes
- Advantages:
- Easier to implement and reason about
- Guarantees global ordering of operations
- Disadvantages:
- Single point of failure affects entire system
- Limited scalability as system grows (bottleneck at coordinator)
- Examples:
- Central lock server for distributed mutual exclusion
- Primary-backup replication in distributed databases
Decentralized Synchronization Techniques
- Provide better fault tolerance and scalability in distributed environments
- Nodes coordinate among themselves without central authority
- Advantages:
- Improved fault tolerance (no single point of failure)
- Better scalability as system grows
- Disadvantages:
- Increased complexity in implementation and reasoning
- Potential for temporary inconsistencies
- Examples:
- Gossip protocols for information dissemination
- Distributed hash tables for peer-to-peer systems
Trade-offs and Considerations
- CAP theorem highlights trade-offs between Consistency, Availability, and Partition tolerance
- Impossible to simultaneously achieve all three in distributed systems
- Eventual consistency models improve performance and availability
- Allow temporary inconsistencies (Amazon's Dynamo DB)
- Time synchronization protocols balance accuracy and resource usage
- NTP: Lower accuracy but less network overhead
- PTP: Higher accuracy but requires more network resources
- Optimistic concurrency control improves performance in low-contention scenarios
- Risk of increased abort rates in high-contention environments
- Synchronous vs asynchronous communication models affect system characteristics
- Synchronous: Predictable latency but lower fault tolerance
- Asynchronous: Better fault tolerance but less predictable performance