Competitive learning and vector quantization are key techniques in unsupervised learning. These methods allow neural networks to discover patterns and structure in data without explicit guidance, forming the basis for many clustering and data compression applications.
In this section, we'll explore how neurons compete to respond to input patterns, creating specialized detectors. We'll also dive into vector quantization for data compression and see how these concepts apply to real-world problems in pattern recognition and feature extraction.
Competitive Learning in Neural Networks
Principles of Competitive Learning
- Competitive learning is an unsupervised learning paradigm in which neurons compete to respond to input patterns
- Leads to the development of specialized neurons that respond to specific input patterns (handwritten digits, facial features)
- Neurons are organized in a layer, and each neuron has a weight vector that determines its sensitivity to different input patterns
- The winner-takes-all principle states that during the learning process, the neuron with the highest activation is declared the winner
- The winning neuron's weight vector is most similar to the input pattern
- The winning neuron is allowed to update its weights to become even more similar to the input pattern
- The learning process in competitive learning involves adjusting the weights of the winning neuron to move closer to the input pattern
- The weights of the losing neurons remain unchanged or are adjusted to move away from the input pattern (depending on the specific algorithm)
Benefits and Applications of Competitive Learning
- Competitive learning allows the network to automatically discover and adapt to the underlying structure of the input data
- Leads to the formation of clusters or categories (customer segments, document topics)
- Competitive learning can be used for unsupervised feature extraction and dimensionality reduction
- The weight vectors of the neurons represent the most salient or informative features of the input data
- Applications of competitive learning include data compression, clustering, pattern recognition, and visualization
- Commonly used in self-organizing maps (SOMs) and vector quantization (VQ) algorithms
Vector Quantization for Data Compression

Principles of Vector Quantization
- Vector quantization (VQ) is a technique used for data compression and clustering that relies on the principles of competitive learning
- In VQ, a codebook (a set of representative vectors) is generated from the input data
- Each input vector is replaced by the index of the closest codebook vector, resulting in a compressed representation of the data
- The codebook vectors are typically obtained through an iterative training process
- The codebook vectors are initialized randomly and then updated using competitive learning algorithms to minimize the quantization error (the difference between the input vectors and their closest codebook vectors)
Applications of Vector Quantization
- VQ can be used for lossy data compression, where the goal is to reduce the amount of data required to represent the input vectors
- Minimizes the distortion introduced by the compression process (image compression, speech coding)
- VQ is also used for clustering, as the codebook vectors can be seen as cluster centers
- Each input vector is assigned to the cluster represented by its closest codebook vector
- VQ has applications in various domains, including image and signal processing, speech recognition, and information retrieval
- Allows for efficient storage, transmission, and retrieval of large datasets (multimedia databases, communication systems)
Implementing Competitive Learning Algorithms
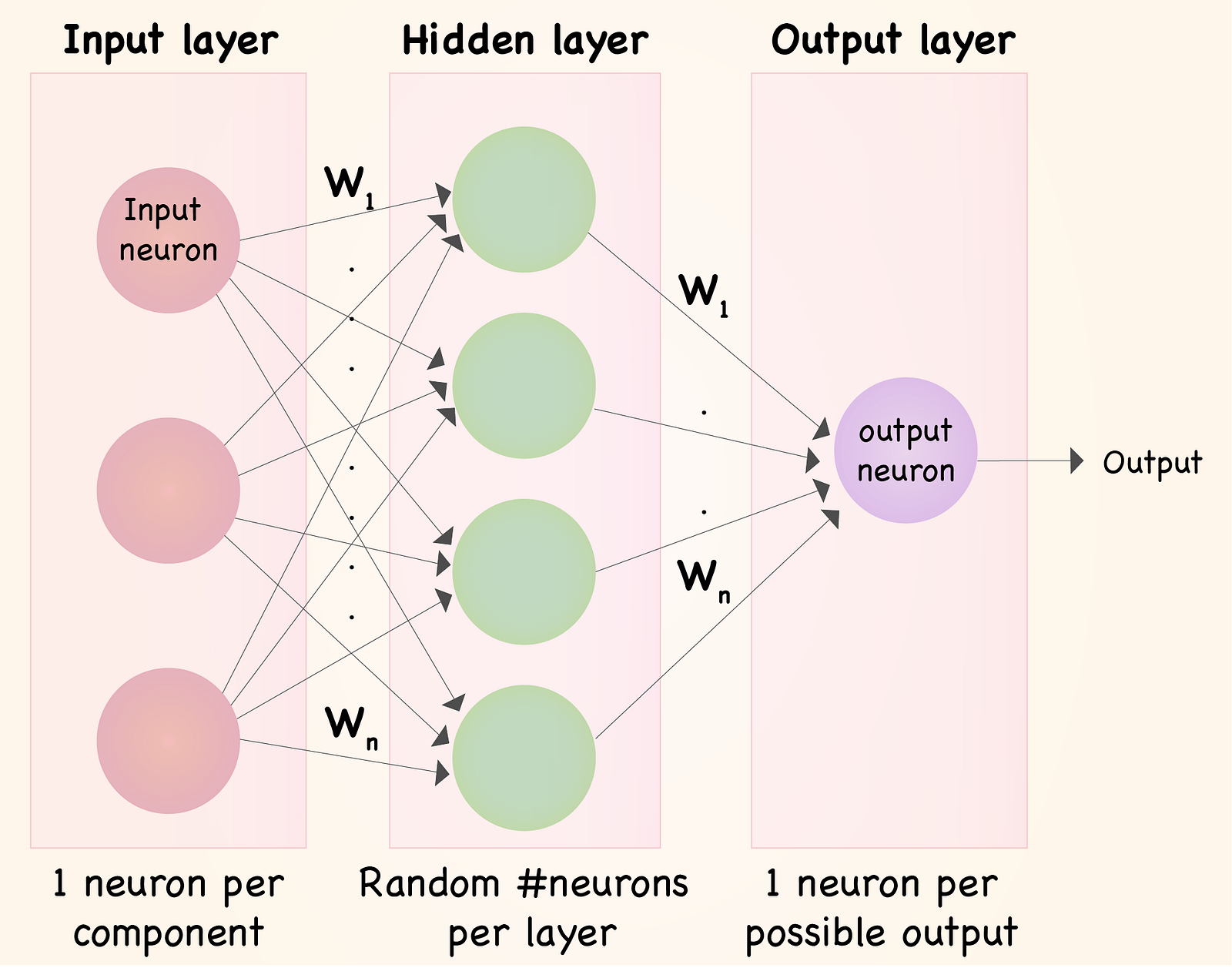
Network Architecture and Training Process
- To implement competitive learning algorithms, you need to define the architecture of the network
- Specify the number of neurons in the competitive layer and the dimensionality of the input and weight vectors
- The training process involves presenting input patterns to the network and computing the activation of each neuron
- The activation is based on the similarity between the neuron's weight vector and the input pattern
- The winning neuron is identified using the winner-takes-all principle (the neuron with the highest activation)
- The weights of the winning neuron are updated to move closer to the input pattern
- The learning rate parameter controls the magnitude of the weight update
- The training process is repeated for a fixed number of iterations or until a convergence criterion is met
- Convergence criteria can include a minimum change in the weight vectors or a maximum number of iterations
Pattern Recognition and Feature Extraction
- After training, the competitive learning network can be used for pattern recognition
- New input patterns are presented to the network, and the winning neuron represents the category or cluster to which the input pattern belongs
- Competitive learning can also be used for feature extraction
- The weight vectors of the neurons represent the most salient or informative features of the input data
- Allows for dimensionality reduction and improved representation of the data (face recognition, document clustering)
Competitive Learning Variants: LVQ vs Others
Learning Vector Quantization (LVQ)
- Learning Vector Quantization (LVQ) is a supervised variant of competitive learning
- Incorporates class label information during training to improve the classification performance of the network
- In LVQ, the codebook vectors are assigned class labels
- The training process involves updating the codebook vectors to move closer to the input patterns of the same class and away from the input patterns of different classes
- LVQ uses a different update rule for the codebook vectors compared to unsupervised competitive learning
- Takes into account the class labels of the input patterns and the codebook vectors
- LVQ can be further extended to variants such as LVQ2 and LVQ3
- Introduce additional update rules and parameters to improve the classification performance and stability of the network
Other Competitive Learning Variants
- Self-Organizing Maps (SOM) arrange the neurons in a two-dimensional grid
- Preserve the topological structure of the input data (neighboring neurons respond to similar input patterns)
- Adaptive Resonance Theory (ART) adds a vigilance parameter to control the formation of new categories or clusters
- Allows for incremental learning and the creation of new categories when the input pattern is sufficiently different from existing categories
- Growing Neural Gas (GNG) dynamically adds and removes neurons during the learning process
- Adapts the network structure to the complexity of the input data (useful for non-stationary data distributions)
- The choice of the specific competitive learning variant depends on the nature of the problem, the availability of labeled data, and the desired properties of the learned representation
- Topology preservation, classification accuracy, incremental learning, and network complexity are important considerations