Neural networks revolutionize pattern recognition by mimicking the brain's structure. These powerful algorithms learn complex patterns from data, using interconnected layers of artificial neurons to process information and make predictions.
From simple feedforward networks to advanced architectures like CNNs and RNNs, neural networks excel at various tasks. They're evaluated using metrics like accuracy and F1-score, with techniques like cross-validation and regularization improving their performance in real-world applications.
Pattern Recognition Fundamentals
Key Concepts
- Pattern recognition involves the automated detection, classification, and identification of patterns, regularities, or similarities in data
- Neural networks are a class of machine learning algorithms inspired by the structure and function of biological neural networks in the brain, capable of learning complex patterns from data
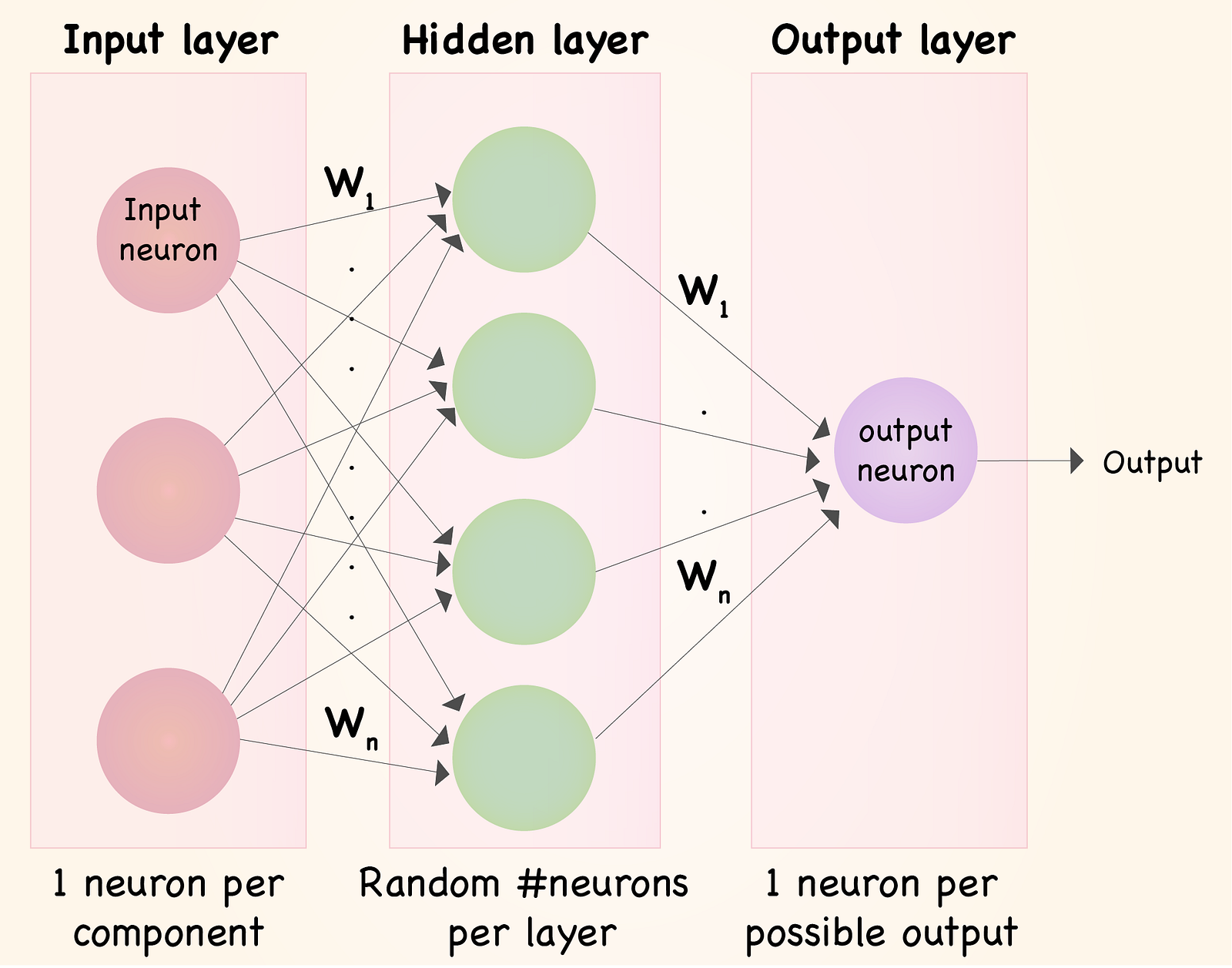
- The basic building block of a neural network is an artificial neuron or node, which receives weighted inputs, applies an activation function, and produces an output signal
- Neural networks consist of interconnected layers of neurons: an input layer, one or more hidden layers, and an output layer. The number of neurons in each layer and the number of layers determine the network's architecture
Training and Activation Functions
- The weights of the connections between neurons are adjusted during the training process using optimization algorithms, such as gradient descent, to minimize the difference between the network's predictions and the true labels
- Activation functions, such as sigmoid, tanh, ReLU, and softmax, introduce non-linearity into the network, enabling it to learn complex, non-linear decision boundaries
- The universal approximation theorem states that a feedforward neural network with at least one hidden layer can approximate any continuous function, given sufficient neurons in the hidden layer
Neural Network Architectures
Feedforward and Convolutional Neural Networks
- Feedforward neural networks, also known as multi-layer perceptrons (MLPs), are the most basic type of neural networks used for pattern recognition. They consist of an input layer, one or more hidden layers, and an output layer, with information flowing in one direction from input to output
- Convolutional neural networks (CNNs) are specialized neural network architectures designed for processing grid-like data, such as images. They employ convolutional layers to learn local features and pooling layers to reduce spatial dimensions
Recurrent and Autoencoder Neural Networks
- Recurrent neural networks (RNNs) are designed to process sequential data, such as time series or natural language. They maintain an internal state or memory that allows them to capture temporal dependencies and context
- Long short-term memory (LSTM) networks and gated recurrent units (GRUs) are variants of RNNs that address the vanishing gradient problem and can effectively learn long-term dependencies
- Autoencoders are unsupervised neural networks that learn efficient representations of input data by encoding it into a lower-dimensional latent space and reconstructing the original input from the latent representation
- Siamese networks consist of two or more identical subnetworks that share weights and are trained to learn a similarity metric between input pairs, useful for tasks like face verification or signature matching
Neural Network Performance Evaluation

Evaluation Metrics
- Performance evaluation is crucial to assess the effectiveness of neural networks in pattern recognition tasks and to compare different models or architectures
- The choice of evaluation metrics depends on the specific pattern recognition problem, such as classification, regression, or clustering
- For classification tasks, common evaluation metrics include accuracy, precision, recall, F1-score, and the confusion matrix, which provide insights into the model's ability to correctly classify instances of different classes
- Receiver operating characteristic (ROC) curves and area under the ROC curve (AUC) are used to evaluate the performance of binary classifiers at different classification thresholds
- For regression tasks, evaluation metrics such as mean squared error (MSE), mean absolute error (MAE), and coefficient of determination (R-squared) measure the model's ability to predict continuous values
Techniques to Improve Performance
- Cross-validation techniques, such as k-fold cross-validation and stratified k-fold cross-validation, are used to assess the model's performance on unseen data and to detect overfitting or underfitting
- Regularization techniques, like L1 and L2 regularization, dropout, and early stopping, help prevent overfitting and improve the generalization ability of neural networks
Real-World Pattern Recognition Implementation
Data Preprocessing and Model Design
- Implementing neural networks for pattern recognition involves several steps: data preprocessing, model architecture design, training, and evaluation
- Data preprocessing techniques, such as normalization, standardization, and feature scaling, ensure that the input features have similar scales and distributions, improving the convergence and stability of the training process
- Data augmentation techniques, like rotation, flipping, and cropping, can be applied to increase the diversity of the training data and improve the model's robustness to variations in input patterns
- The choice of neural network architecture depends on the specific pattern recognition task and the nature of the input data. Factors to consider include the number of layers, the number of neurons per layer, and the type of layers (e.g., convolutional, recurrent, or fully connected)
Training and Optimization
- The selection of appropriate loss functions, such as cross-entropy for classification or mean squared error for regression, guides the optimization process during training
- Optimization algorithms, like stochastic gradient descent (SGD), Adam, or RMSprop, are used to update the network's weights iteratively based on the computed gradients of the loss function
- Hyperparameter tuning involves selecting optimal values for parameters such as learning rate, batch size, number of epochs, and regularization strength to achieve the best performance on the validation set
- Transfer learning can be employed to leverage pre-trained neural networks, such as VGG, ResNet, or Inception, as feature extractors or for fine-tuning on specific pattern recognition tasks, reducing the need for large amounts of labeled data and accelerating the training process