Measures of central tendency and dispersion are key tools for summarizing data. They help us understand the typical values in a dataset and how spread out the data is. These measures are crucial for making sense of large amounts of information quickly.
The mean, median, and mode give us a central value, while range, variance, and standard deviation show data spread. Choosing the right measure depends on the data type and distribution, ensuring we get an accurate picture of what's going on.
Central Tendency Measures
Mean, Median, and Mode
- Calculate the mean by summing all values and dividing by the number of values
- The mean is sensitive to extreme values (outliers) in the dataset
- Example: For the dataset {1, 2, 3, 4, 5}, the mean is (1 + 2 + 3 + 4 + 5) / 5 = 3
- Determine the median by ordering the dataset from lowest to highest and selecting the middle value
- For an even number of values, calculate the average of the two middle values
- The median is less affected by outliers compared to the mean
- Example: For the dataset {1, 2, 3, 4, 5}, the median is 3
- Identify the mode as the most frequently occurring value in a dataset
- A dataset can have no mode (if no value repeats), one mode (unimodal), or multiple modes (bimodal or multimodal)
- Example: For the dataset {1, 2, 2, 3, 4, 5}, the mode is 2
Interpreting Central Tendency
- Understand what a "typical" or "central" value represents in the context of the data and research question
- Consider the level of measurement (nominal, ordinal, interval, or ratio) when selecting appropriate measures
- The mean is most appropriate for interval or ratio data
- The median is suitable for ordinal data or datasets with extreme values
- The mode is the only measure applicable to nominal (categorical) data
- Assess the distribution of the data, including skewness and the presence of outliers
- For skewed distributions or datasets with outliers, the median may be more appropriate than the mean
Data Dispersion Metrics

Range, Variance, and Standard Deviation
- Calculate the range by subtracting the minimum value from the maximum value in a dataset
- Range provides a simple measure of dispersion
- Example: For the dataset {1, 2, 3, 4, 5}, the range is 5 - 1 = 4
- Determine the variance by summing the squared differences between each value and the mean, then dividing by the number of values (for population variance) or the number of values minus one (for sample variance)
- Variance measures the average squared deviation from the mean, quantifying how far individual values are from the mean
- Example: For the dataset {1, 2, 3, 4, 5}, the population variance is
- Calculate the standard deviation by taking the square root of the variance
- Standard deviation expresses dispersion in the same units as the original data and is often preferred over variance for interpretability
- Example: For the dataset {1, 2, 3, 4, 5}, the population standard deviation is
Interpreting Dispersion
- Recognize that higher values of range, variance, and standard deviation indicate greater dispersion or variability in the dataset
- Consider the sensitivity of range to outliers and its lack of information about the distribution of values between the minimum and maximum
- Understand that variance and standard deviation require interval or ratio data and are sensitive to outliers
- These measures may not be appropriate for skewed distributions
Properties of Measures
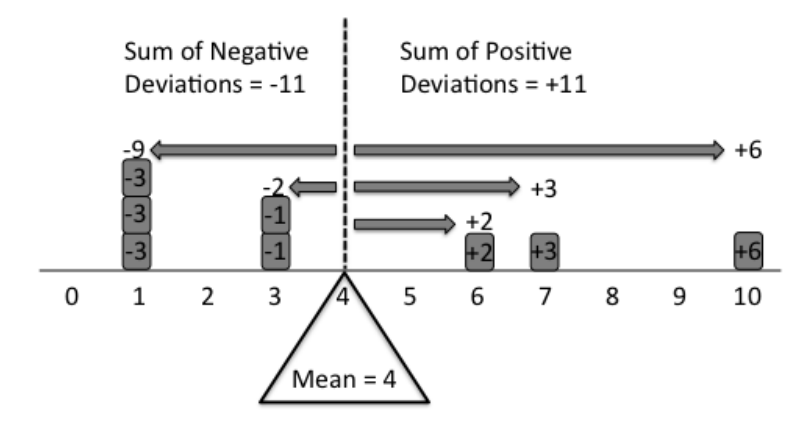
Central Tendency Measures
- The mean is influenced by extreme values and may not be representative of the central tendency if the data is skewed or has outliers
- The median is robust to outliers and skewed distributions, making it a better measure of central tendency for ordinal data or datasets with extreme values
- The mode does not provide information about the magnitude of values and is the only measure applicable to nominal (categorical) data
Dispersion Measures
- Range is easy to calculate but sensitive to outliers and does not consider the distribution of values between the minimum and maximum
- Variance and standard deviation are more informative than range but require interval or ratio data
- These measures are sensitive to outliers and may not be appropriate for skewed distributions
Choosing Appropriate Measures
Considering Data Type and Distribution
- Select measures based on the level of measurement (nominal, ordinal, interval, or ratio)
- The mean and standard deviation are appropriate for interval and ratio data
- The median and range are suitable for ordinal data
- The mode can be used for nominal data
- Assess the distribution of the data, including skewness and the presence of outliers
- For skewed distributions or datasets with outliers, the median and interquartile range may be more appropriate than the mean and standard deviation
Aligning with Research Objectives
- Evaluate the research question and the intended use of the measures
- If the goal is to identify the most common category, the mode would be appropriate
- If the aim is to compare the variability of different groups, the standard deviation or coefficient of variation may be suitable
- When reporting measures of central tendency and dispersion, clearly state which measures were used and justify their selection based on the nature of the data and research objectives