🧠Machine Learning Engineering Unit 5 Review
5.3 Bias-Variance Tradeoff
5.3 Bias-Variance Tradeoff
Unit & Topic Study Guides
Machine Learning Engineering Fundamentals
Data Prep & Feature Engineering for ML
Supervised Learning Algorithms
Unsupervised Learning Algorithms
Model Selection and Evaluation
Hyperparameter Tuning & Optimization
Distributed Computing for ML
Cloud-Based Scalable Machine Learning
Automated ML Pipelines in Engineering
Deploying ML Models
A/B Testing and Experimentation
Monitoring and Maintaining ML Systems
Ethical Considerations in ML
Bias Detection & Mitigation in ML
Case Studies in Machine Learning Engineering
The bias-variance tradeoff is a fundamental concept in machine learning that balances model simplicity with flexibility. It's crucial for understanding how models can underfit or overfit data, impacting their ability to generalize to new examples.
This topic connects to model selection and evaluation by highlighting the importance of finding the right model complexity. It guides us in choosing models that strike an optimal balance between bias and variance, leading to better performance on unseen data.
Bias and Variance in Machine Learning
Defining Bias and Variance
- Bias represents the error introduced by approximating complex real-world problems with simplified models leading to underfitting
- Variance measures a model's sensitivity to small fluctuations in training data potentially causing overfitting
- Bias-variance tradeoff balances underfitting and overfitting to optimize model performance
- Total error of a model decomposes into bias, variance, and irreducible error components
- Bias and variance exhibit an inverse relationship where reducing one often increases the other
Impact of Model Complexity
- High bias models have low complexity and may miss important data patterns (linear regression for non-linear relationships)
- High variance models are overly complex and sensitive to noise in the data (deep neural networks with limited training data)
- Optimal balance between bias and variance minimizes overall prediction error
- Simple models (decision stumps) tend to have high bias and low variance
- Complex models (deep neural networks) often have low bias but high variance
Model Complexity vs Bias-Variance Tradeoff
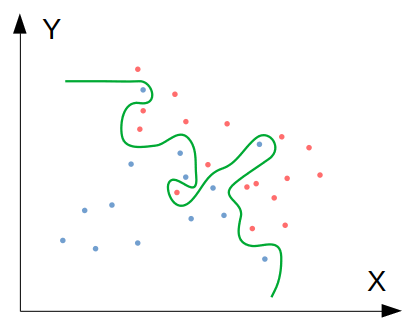
Understanding Model Complexity
- Model complexity refers to the flexibility or number of parameters in a machine learning model
- Increasing model complexity typically decreases bias while increasing variance
- Simple models with low complexity often lead to underfitting (single-layer perceptron)
- Complex models with high flexibility can result in overfitting (high-degree polynomial regression)
- Optimal model complexity minimizes the sum of squared bias and variance
Visualizing and Assessing Complexity
- Learning curves visualize the relationship between model complexity, training error, and validation error
- Cross-validation techniques assess model performance across varying levels of complexity
- Training error typically decreases with increased complexity
- Validation error often follows a U-shaped curve, decreasing initially then increasing as overfitting occurs
- Gap between training and validation error widens with excessive complexity indicating overfitting
High Bias and High Variance Scenarios
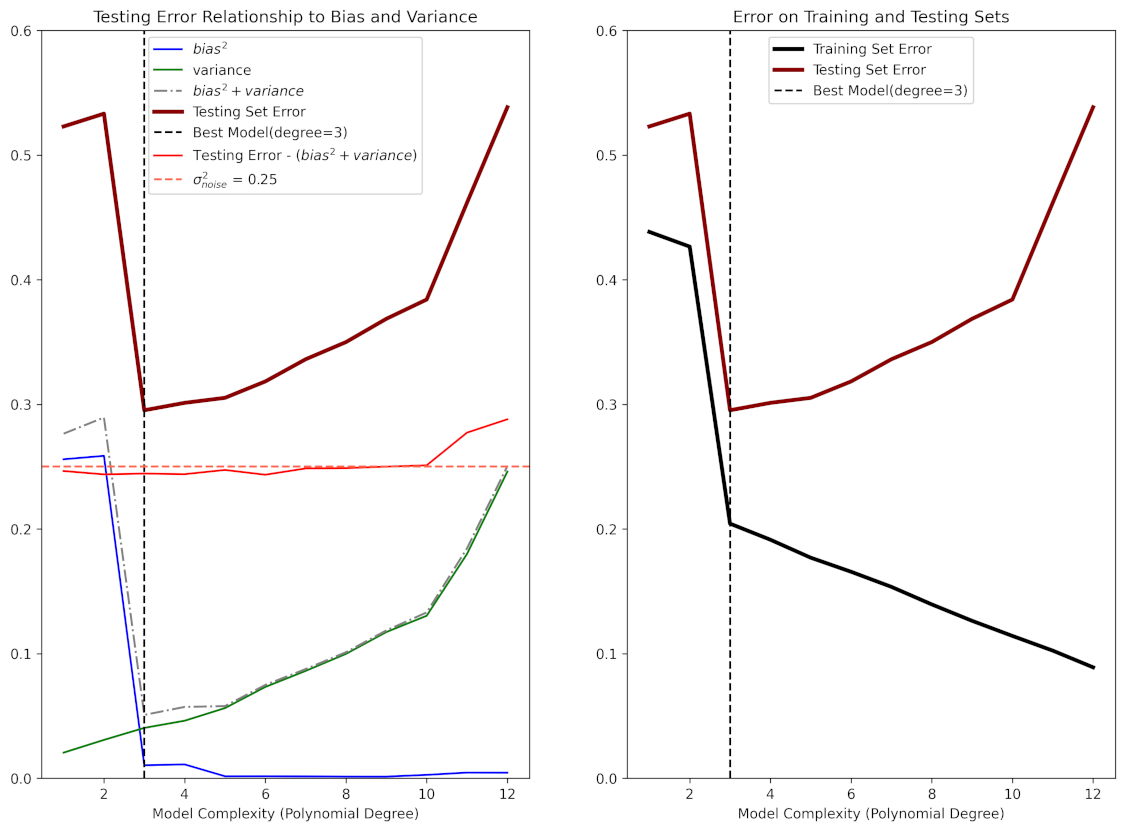
Identifying Bias and Variance Issues
- High bias scenarios show poor performance on both training and validation data indicating underfitting
- High variance scenarios exhibit excellent training performance but poor validation performance suggesting overfitting
- Analyzing learning curves helps diagnose bias and variance issues
- Large gap between training and test error suggests high variance
- High error on both training and test sets indicates high bias
Mitigating Bias and Variance
- Address high bias by increasing model complexity, adding relevant features, or reducing regularization
- Mitigate high variance by increasing training data size, applying feature selection, or using regularization techniques
- Ensemble methods (random forests, gradient boosting) reduce both bias and variance simultaneously
- Early stopping prevents overfitting by halting training when validation error begins to increase
- Feature engineering creates new informative features to reduce bias without increasing variance
Regularization for Bias-Variance Balance
Types of Regularization
- Regularization prevents overfitting by adding a penalty term to the loss function
- L1 regularization (Lasso) adds absolute value of coefficients to loss function promoting sparsity (feature selection)
- L2 regularization (Ridge) adds squared magnitude of coefficients encouraging smaller, evenly distributed weights
- Elastic Net combines L1 and L2 regularization balancing feature selection and coefficient shrinkage
Implementing Regularization
- Regularization strength (lambda or alpha) controls the trade-off between model complexity and fitting training data
- Cross-validation selects optimal regularization strength for a given problem
- Dropout in neural networks randomly deactivates neurons during training to reduce overfitting
- Pruning in decision trees removes branches with little impact on performance to reduce model complexity
- Feature engineering creates informative features to improve model performance without increasing complexity