🧠Machine Learning Engineering Unit 10 Review
10.4 MLOps Best Practices
10.4 MLOps Best Practices
Unit & Topic Study Guides
Machine Learning Engineering Fundamentals
Data Prep & Feature Engineering for ML
Supervised Learning Algorithms
Unsupervised Learning Algorithms
Model Selection and Evaluation
Hyperparameter Tuning & Optimization
Distributed Computing for ML
Cloud-Based Scalable Machine Learning
Automated ML Pipelines in Engineering
Deploying ML Models
A/B Testing and Experimentation
Monitoring and Maintaining ML Systems
Ethical Considerations in ML
Bias Detection & Mitigation in ML
Case Studies in Machine Learning Engineering
MLOps best practices are crucial for deploying and maintaining machine learning models effectively. They combine principles from DevOps, data engineering, and ML to ensure reliable, efficient, and scalable model production.
Key practices include automation, continuous integration/delivery, versioning, and monitoring. These help reduce technical debt, improve model quality, and speed up development while ensuring reproducibility and scalability in real-world applications.
MLOps principles and practices
Foundations of MLOps
- MLOps combines Machine Learning, DevOps, and Data Engineering to deploy and maintain ML models in production reliably and efficiently
- ML lifecycle encompasses stages from data preparation and model development to deployment, monitoring, and continuous improvement of models in production environments
- Key principles include automation, continuous integration and delivery, versioning, monitoring, and collaboration between data scientists, ML engineers, and operations teams
- MLOps practices reduce technical debt, improve model quality, and increase the speed of model development and deployment while ensuring reproducibility and scalability
- Infrastructure-as-Code (IaC) manages and provisions computing infrastructure through machine-readable definition files, rather than manual processes (Terraform, AWS CloudFormation)
Feature Management and Lineage Tracking
- Feature stores serve as centralized repositories for storing, managing, and serving machine learning features
- Maintain consistency between training and serving environments
- Enable feature reuse across different models and teams
- Examples include Feast, Tecton, and AWS Feature Store
- Data and model lineage tracking ensures reproducibility and facilitates debugging and auditing of ML systems
- Tracks the origin and transformations of data used in model training
- Records the sequence of steps and configurations used to create a model
- Tools like MLflow and DVC (Data Version Control) provide lineage tracking capabilities
Best Practices for MLOps Implementation
- Implement automated testing for data pipelines, model training, and deployment processes
- Use containerization technologies (Docker) for creating reproducible and portable ML environments
- Employ orchestration tools (Kubernetes, Apache Airflow) to manage complex ML workflows
- Establish clear communication channels between data scientists, ML engineers, and operations teams
- Implement robust error handling and logging mechanisms throughout the ML pipeline
- Regularly review and update MLOps practices to incorporate new tools and methodologies
CI/CD pipelines for ML models
CI/CD Pipeline Components for ML
- CI/CD for ML models extends traditional software CI/CD practices to include data pipelines, model training, and model deployment processes
- Automated testing in ML CI/CD pipelines includes:
- Unit tests for individual components of ML code
- Integration tests to ensure different parts of the ML system work together
- Data validation tests to check data quality and consistency
- Model performance evaluation tests to assess model accuracy and other metrics
- A/B testing to compare new models against existing ones
- Model registries store and manage ML models, their versions, and associated metadata
- Facilitate seamless integration with CI/CD pipelines
- Examples include MLflow Model Registry, Amazon SageMaker Model Registry
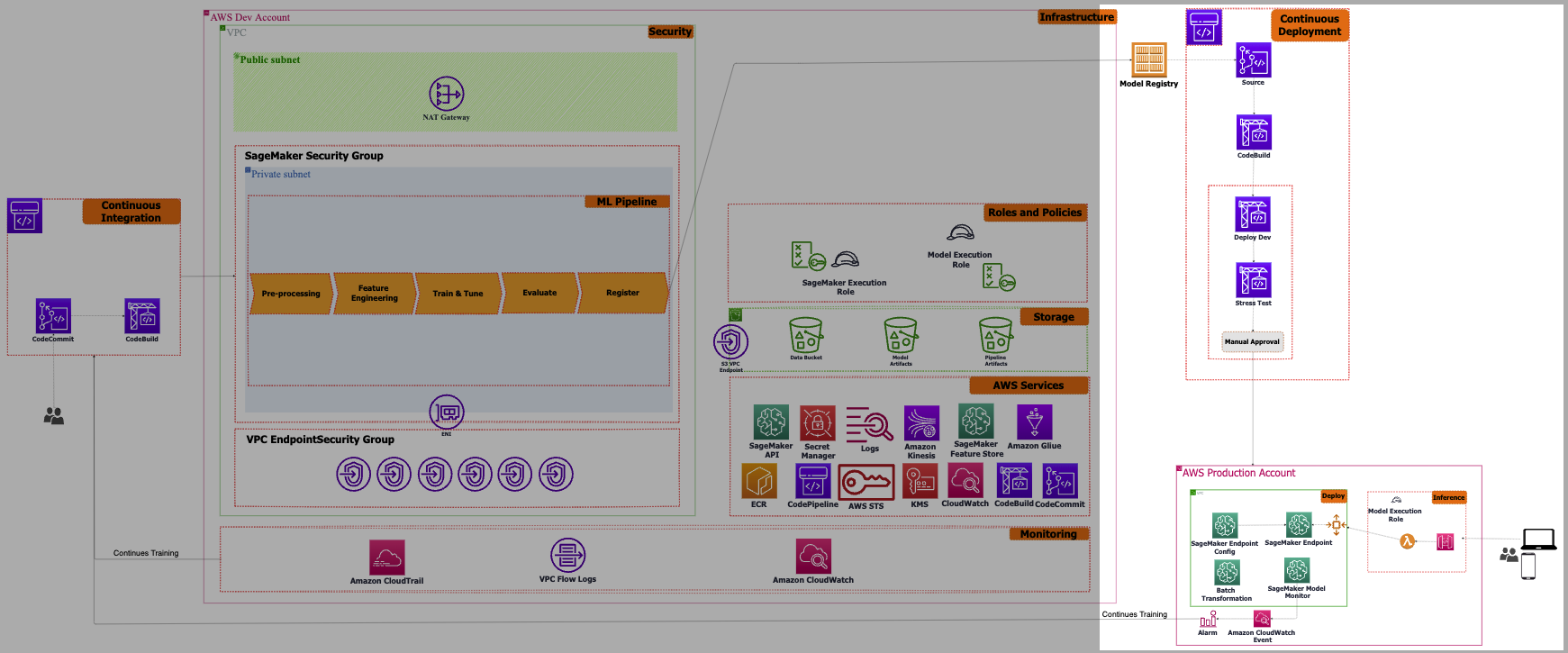
Containerization and Orchestration
- Containerization technologies (Docker) create reproducible and portable ML environments across different stages of the CI/CD pipeline
- Orchestration tools manage the deployment and scaling of ML models in production environments
- Kubernetes for container orchestration
- Cloud-native services (AWS ECS, Google Cloud Run) for serverless deployments
- Feature flags and canary releases gradually roll out new models or features to production
- Minimize risk and enable quick rollbacks if issues arise
- Tools like LaunchDarkly or Split.io can be used for feature flagging
Automated Model Retraining and Deployment
- Implement automated model retraining pipelines to periodically update models with new data
- Ensure models remain accurate and relevant over time
- Trigger retraining based on schedule or performance thresholds
- Continuous deployment strategies for ML models:
- Blue-Green deployments switch between two identical environments
- Canary releases gradually increase traffic to new model versions
- Shadow deployments run new models in parallel with existing ones for comparison
- Implement rollback mechanisms to quickly revert to previous model versions if issues are detected
Model performance and data drift monitoring
Performance Monitoring Techniques
- Track key metrics to detect degradation in model performance over time
- Accuracy, precision, recall for classification models
- Mean Absolute Error (MAE), Root Mean Square Error (RMSE) for regression models
- Business-specific KPIs (conversion rates, revenue impact)
- Implement monitoring dashboards and automated alerts
- Tools like Grafana or Prometheus for visualization
- Set up alerting thresholds for critical performance metrics
- Utilize A/B testing and shadow deployments to compare new models against existing ones
- Gradually increase traffic to new models while monitoring performance
- Conduct statistical significance tests to validate improvements
Data and Concept Drift Detection
- Data drift refers to changes in the statistical properties of input data over time
- Monitor feature distributions using statistical tests (Kolmogorov-Smirnov test, Chi-squared test)
- Visualize drift using techniques like Population Stability Index (PSI)
- Concept drift occurs when the relationship between input features and target variables changes
- Monitor prediction confidence scores over time
- Implement adaptive learning techniques to automatically update models
- Techniques for detecting drift:
- Statistical tests (t-tests, ANOVA)
- Distribution comparisons (KL divergence, Wasserstein distance)
- Monitoring of model prediction confidence scores
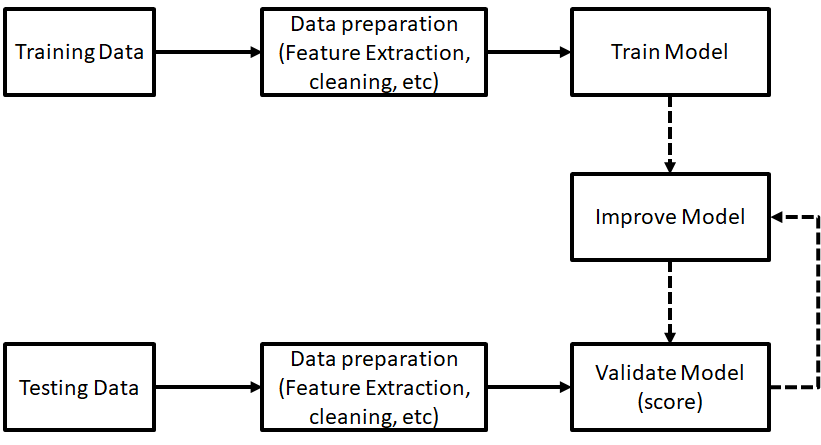
Explainable AI and Bias Detection
- Employ Explainable AI (XAI) techniques to interpret model decisions
- SHAP (SHapley Additive exPlanations) values for feature importance
- LIME (Local Interpretable Model-agnostic Explanations) for local interpretability
- Identify potential biases in production models
- Monitor fairness metrics across different demographic groups
- Implement bias mitigation techniques (reweighing, prejudice remover)
- Conduct regular model audits to ensure ethical and unbiased decision-making
- Review model predictions across various subgroups
- Analyze the impact of model decisions on different populations
Model governance and versioning strategies
Model Governance Framework
- Establish policies, procedures, and best practices for managing ML models throughout their lifecycle
- Ensure compliance with regulatory requirements (GDPR, CCPA)
- Adhere to ethical guidelines for AI development and deployment
- Implement model risk management practices
- Assess potential risks associated with ML models (bias, fairness, regulatory compliance)
- Develop mitigation strategies for identified risks
- Conduct regular audits and reviews of ML systems
- Ensure ongoing compliance with governance policies
- Identify areas for improvement in the MLOps process
Version Control and Reproducibility
- Extend version control systems to track:
- Code (model architecture, training scripts)
- Data (training and validation datasets)
- Model artifacts (trained model weights, hyperparameters)
- Environment configurations (dependencies, libraries)
- Enable complete reproducibility of ML experiments and deployments
- Tools like DVC (Data Version Control) for data and model versioning
- Git for code versioning
- Docker for environment reproducibility
- Implement provenance tracking to record the complete lineage of data and model transformations
- From raw data ingestion to final model deployment
- Facilitate audits and troubleshooting of ML pipelines
Documentation and Access Control
- Use standardized documentation formats to capture essential information:
- Model cards detail model specifications, intended use, and limitations
- Datasheets describe dataset characteristics, collection methods, and potential biases
- Implement access control and role-based permissions
- Manage who can view, modify, or deploy models and associated resources
- Ensure data privacy and security throughout the ML lifecycle
- Establish clear communication channels for sharing model information
- Create centralized knowledge bases for model documentation
- Implement approval workflows for model deployment and updates