One-sample tests for means are crucial tools in statistics. They help us determine if a sample's average differs significantly from a known or hypothesized population mean. These tests come in two flavors: z-tests for large samples or known population standard deviations, and t-tests for smaller samples with unknown standard deviations.
Understanding when to use each test and how to interpret the results is key. By calculating test statistics and comparing them to critical values or p-values, we can make informed decisions about our hypotheses. This process allows us to draw meaningful conclusions from our data in various real-world scenarios.
One-Sample Tests for Means
Z-test vs t-test for means
- Use a z-test when the population standard deviation () is known or the sample size is large (n ≥ 30), even if the population standard deviation is unknown
- Use a t-test when the population standard deviation () is unknown and the sample size is small (n < 30)
- Example: Testing the mean weight of a product with a known standard deviation from historical data (z-test) vs testing the mean height of students in a small class (t-test)

One-sample z-test for means
- State the null and alternative hypotheses
- population mean equals the hypothesized value
- two-tailed, right-tailed, or left-tailed
- Calculate the z-score using the formula
- represents the sample mean
- represents the hypothesized population mean
- represents the population standard deviation
- represents the sample size
- Compare the calculated z-score to the critical z-value or use the p-value to make a decision
- Reject if two-tailed, right-tailed, or left-tailed
- represents the significance level (commonly 0.05)
- Example: Testing if the mean weight of a product differs from the advertised weight
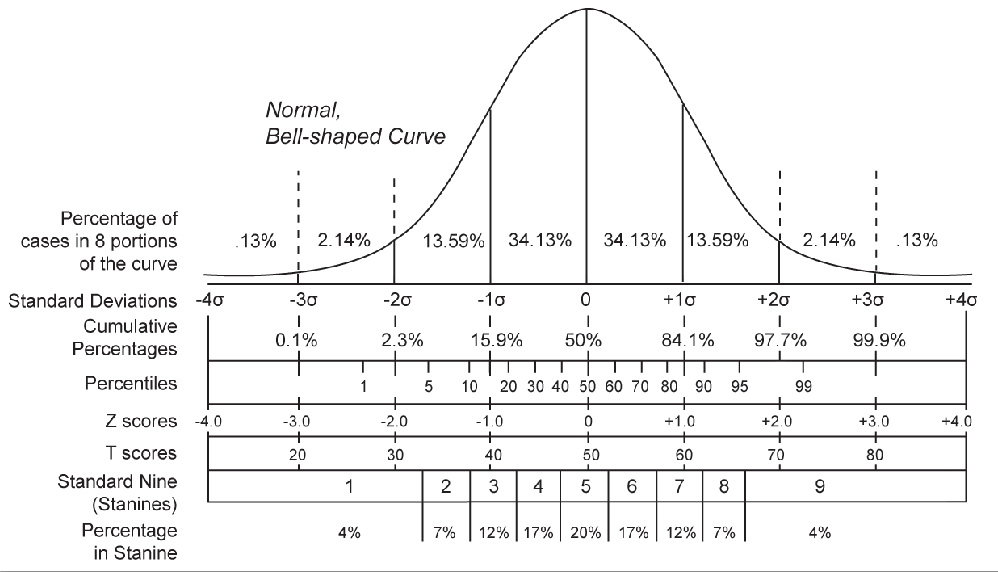
One-sample t-test for means
- State the null and alternative hypotheses (same as z-test)
- Calculate the t-score using the formula
- represents the sample standard deviation
- Determine the degrees of freedom
- Compare the calculated t-score to the critical t-value or use the p-value to make a decision
- Reject if two-tailed, right-tailed, or left-tailed
- Example: Testing if the mean height of students in a small class differs from the national average
P-values in mean testing
- The p-value represents the probability of obtaining a test statistic as extreme as or more extreme than the observed value, assuming the null hypothesis is true
- Calculate the p-value using the z-score or t-score and the corresponding distribution (standard normal or t-distribution)
- Interpret the p-value
- Reject (statistically significant result) if p-value ≤
- Fail to reject (statistically insignificant result) if p-value >
- A smaller p-value provides stronger evidence against the null hypothesis
- Example: A p-value of 0.01 indicates strong evidence against the null hypothesis, while a p-value of 0.25 suggests weak evidence against the null hypothesis