One-way ANOVA is a key statistical method for comparing means across multiple groups in biostatistics. It builds on t-test principles, allowing researchers to analyze variance among three or more independent groups simultaneously, which is crucial for identifying significant differences in experimental studies.
This technique relies on assumptions of independence, normality, and homogeneity of variances. It breaks down variability into between-group and within-group components, using the F-statistic to determine if group differences are statistically significant. Post-hoc tests help pinpoint specific group differences after a significant ANOVA result.
Overview of one-way ANOVA
- Fundamental statistical technique in biostatistics used to compare means across multiple groups
- Extends the principles of t-tests to analyze variance among three or more independent groups
- Crucial for identifying significant differences in experimental or observational studies with multiple treatment levels
Assumptions of one-way ANOVA
Independence of observations
- Requires each data point to be unrelated to others within and between groups
- Violated when samples are dependent (paired data) or clustered (family members)
- Crucial for maintaining the validity of statistical inferences and avoiding inflated Type I error rates
Normal distribution
- Assumes the dependent variable is approximately normally distributed within each group
- Assessed using visual methods (Q-Q plots) or statistical tests (Shapiro-Wilk test)
- Robust to slight deviations from normality, especially with larger sample sizes (n > 30 per group)
Homogeneity of variances
- Assumes equal variances across all groups being compared
- Tested using Levene's test or Bartlett's test
- Violation can lead to increased Type I error rates, especially with unequal sample sizes
- Alternative tests (Welch's ANOVA) can be used when this assumption is violated
Components of one-way ANOVA
Between-group variability
- Measures the variation in group means from the overall mean
- Calculated as the sum of squared differences between group means and grand mean
- Larger between-group variability suggests greater differences among groups
- Influenced by the effect of the independent variable on the dependent variable
Within-group variability
- Quantifies the spread of individual observations within each group
- Computed as the sum of squared deviations of individual values from their respective group means
- Represents the unexplained variation or "noise" in the data
- Smaller within-group variability increases the power to detect between-group differences
F-statistic
- Ratio of between-group variability to within-group variability
- Calculated as (Mean Square Between) / (Mean Square Within)
- Large F-values indicate greater differences between groups relative to within-group variation
- Used to determine the statistical significance of group differences
Conducting one-way ANOVA

Null vs alternative hypotheses
- Null hypothesis (H0) states all group means are equal
- Alternative hypothesis (Ha) states at least one group mean differs from others
- Formulated mathematically as H0: μ1 = μ2 = ... = μk vs Ha: at least one μi ≠ μj
- Rejection of the null hypothesis suggests significant differences among groups
Degrees of freedom
- Between-groups df = k - 1 (where k is the number of groups)
- Within-groups df = N - k (where N is the total sample size)
- Total df = N - 1
- Used in calculating mean squares and determining the critical F-value
Sum of squares
- Total Sum of Squares (SST) measures total variability in the data
- Between-group Sum of Squares (SSB) quantifies variability explained by group differences
- Within-group Sum of Squares (SSW) represents unexplained variability
- Relationship: SST = SSB + SSW
Mean square
- Mean Square Between (MSB) = SSB / (k - 1)
- Mean Square Within (MSW) = SSW / (N - k)
- Used to calculate the F-statistic: F = MSB / MSW
- Represents average variability between and within groups
Interpreting ANOVA results
P-value significance
- Compares calculated F-statistic to the critical F-value from the F-distribution
- Typically use α = 0.05 as the significance level
- P-value < α suggests rejecting the null hypothesis
- Indicates the probability of observing such extreme results if the null hypothesis were true
Effect size
- Measures the magnitude of the difference between groups
- Common measures include eta-squared (η²) and partial eta-squared (ηp²)
- η² = SSB / SST, ranges from 0 to 1
- Helps assess practical significance beyond statistical significance
Post-hoc tests
- Conducted after a significant ANOVA to identify which specific groups differ
- Common tests include Tukey's HSD, Bonferroni, and Scheffe's method
- Control for multiple comparisons to maintain overall Type I error rate
- Provide pairwise comparisons between all groups
One-way ANOVA vs t-test
- ANOVA extends t-test principles to compare more than two groups simultaneously
- Reduces Type I error rate compared to multiple pairwise t-tests
- More efficient and powerful for multi-group comparisons
- T-test is a special case of ANOVA when comparing only two groups
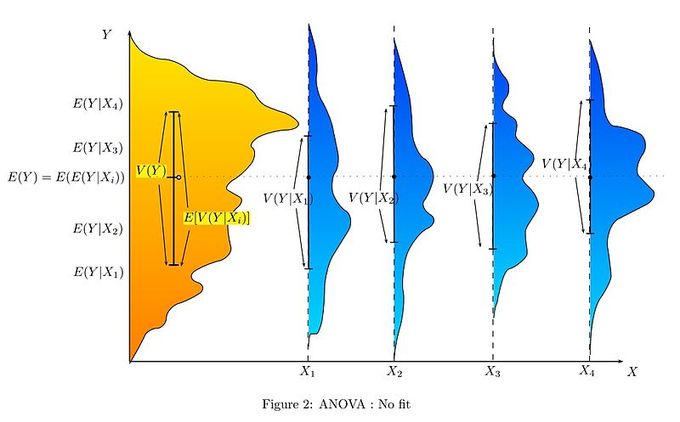
Limitations of one-way ANOVA
- Cannot determine which specific groups differ without post-hoc tests
- Assumes equal importance of all pairwise comparisons
- Sensitive to violations of assumptions, especially with unequal sample sizes
- Does not account for interactions between factors (requires factorial ANOVA)
Applications in biostatistics
Medical research examples
- Comparing effectiveness of multiple drug treatments on blood pressure reduction
- Evaluating the impact of different exercise regimens on bone density
- Assessing variations in patient recovery times across different surgical techniques
Public health studies
- Analyzing differences in disease prevalence across multiple geographic regions
- Comparing the effectiveness of various health education programs on smoking cessation rates
- Evaluating the impact of different nutrition interventions on childhood obesity rates
ANOVA in statistical software
R implementation
- Uses
aov()function for one-way ANOVA - Syntax:
aov(dependent_variable ~ group, data = dataset) - Provides summary statistics, F-value, and p-value
- Additional packages (emmeans, multcomp) for post-hoc analyses
SPSS implementation
- Accessed through Analyze > Compare Means > One-Way ANOVA
- Allows specification of dependent variable and factor (grouping variable)
- Offers options for descriptive statistics, homogeneity tests, and post-hoc comparisons
- Produces ANOVA table with sum of squares, degrees of freedom, F-statistic, and p-value
Reporting one-way ANOVA results
Tables and figures
- ANOVA summary table includes sources of variation, df, SS, MS, F-value, and p-value
- Box plots or error bar plots to visualize group differences
- Descriptive statistics table with means and standard deviations for each group
- Post-hoc test results presented in a matrix or table format
APA format guidelines
- Report F-statistic with degrees of freedom: F(dfbetween, dfwithin) = F-value, p = p-value
- Include effect size measure (η² or ηp²)
- Describe means and standard deviations for each group
- Summarize post-hoc test results, noting significant pairwise differences
- Interpret findings in context of research question and hypotheses