Text preprocessing and feature extraction are crucial steps in text mining and natural language processing. These techniques clean, normalize, and transform raw text data into structured formats suitable for analysis. By removing noise and extracting meaningful features, we can unlock valuable insights from textual information.
From tokenization to stop word removal, these methods lay the foundation for advanced text analysis tasks. Understanding these techniques is essential for anyone looking to harness the power of text data in their projects or research.
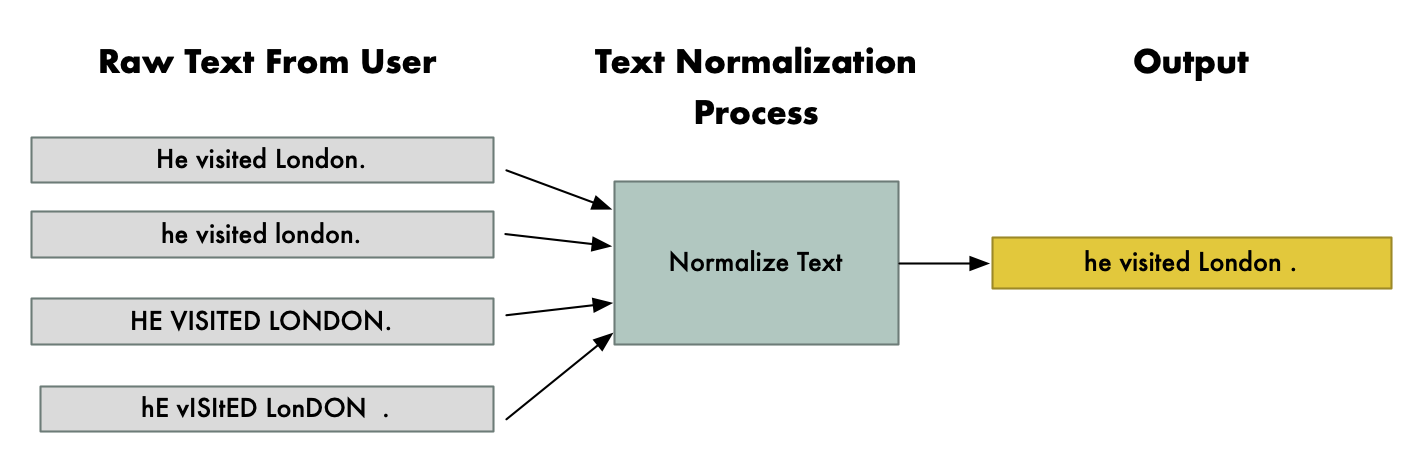
Text Data Cleaning and Normalization
Common Techniques and Challenges
- Text data often contains noise, inconsistencies, and irrelevant information that needs to be cleaned and normalized before analysis
- Common text cleaning techniques include
- Converting text to lowercase
- Removing punctuation and special characters (e.g., !@#$$%^&*)
- Handling whitespace (e.g., removing extra spaces, tabs, or newlines)
- Text normalization involves transforming text into a consistent format
- Standardizing date and number formats (e.g., converting "1st Jan 2021" to "2021-01-01")
- Expanding abbreviations and acronyms (e.g., converting "USA" to "United States of America")
- Handling missing or corrupted text data is crucial
- Removing or imputing missing values based on the specific requirements of the analysis
Regular Expressions for Text Manipulation
- Regular expressions (regex) are powerful tools for pattern matching and text manipulation during the cleaning and normalization process
- Regex allows for complex pattern matching and substitution operations
- Matching specific characters, character classes, or sequences (e.g.,
[a-zA-Z]matches any alphabetic character) - Defining repetition and quantifiers (e.g.,
\d{3}matches exactly three digits) - Capturing and extracting substrings based on patterns (e.g., extracting email addresses or phone numbers)
- Matching specific characters, character classes, or sequences (e.g.,
- Regex can be used to efficiently clean and normalize text data
- Removing unwanted characters or patterns (e.g., removing HTML tags or URLs)
- Replacing or standardizing specific patterns (e.g., converting "1st" to "first")
- Validating and extracting structured information from text (e.g., extracting dates or numbers)
Feature Extraction for Text
Bag-of-Words (BoW) Model
- The bag-of-words (BoW) model represents text as a multiset (bag) of its words, disregarding grammar and word order but keeping multiplicity
- In the BoW model, each unique word in the corpus becomes a feature, and the value of each feature is the frequency or presence of that word in a document
- The BoW model creates a high-dimensional sparse matrix
- Each row represents a document
- Each column represents a unique word in the vocabulary
- The BoW model is simple and computationally efficient but has limitations
- It ignores word order and context, which can lead to loss of semantic information
- It treats all words equally, regardless of their importance or rarity
Term Frequency-Inverse Document Frequency (TF-IDF)
- Term Frequency-Inverse Document Frequency (TF-IDF) is a statistical measure that evaluates the importance of a word to a document in a collection or corpus
- TF (Term Frequency) measures the frequency of a word in a document
- It is calculated as the number of occurrences of a word in a document divided by the total number of words in the document
- IDF (Inverse Document Frequency) measures the informativeness of a word across the corpus
- It is calculated as the logarithm of the total number of documents divided by the number of documents containing the word
- TF-IDF is calculated by multiplying the term frequency (TF) by the inverse document frequency (IDF)
- It helps to reduce the impact of common words and emphasize the importance of rare words
- TF-IDF assigns higher weights to words that are frequent in a document but rare across the corpus
- It captures the importance and uniqueness of words in a document
- TF-IDF is widely used for various text analysis tasks
- Document classification (e.g., categorizing news articles by topic)
- Sentiment analysis (e.g., determining the sentiment of movie reviews)
- Information retrieval (e.g., ranking search results based on relevance)
Stemming and Lemmatization for Word Reduction
Stemming
- Stemming is a rule-based process that removes the suffixes from words to obtain their base or root form, often resulting in incomplete or non-dictionary words
- Common stemming algorithms include
- Porter stemmer: A widely used algorithm that applies a set of rules to remove common suffixes (e.g., "running" becomes "run")
- Snowball stemmer: An improved version of the Porter stemmer with additional language-specific rules
- Lancaster stemmer: A more aggressive stemmer that removes more suffixes but may result in more overstemming
- Stemming can sometimes result in overstemming (removing too much) or understemming (removing too little)
- Overstemming may lead to loss of meaning or merging of unrelated words (e.g., "university" and "universe" both stemmed to "univers")
- Understemming may fail to reduce related words to the same base form (e.g., "run" and "running" remaining separate)
Lemmatization
- Lemmatization is a more sophisticated approach that reduces words to their base or dictionary form (lemma) by considering the word's part of speech and context
- Lemmatization relies on morphological analysis and vocabulary to determine the correct base form of a word
- It uses dictionaries and linguistic rules to map words to their lemmas (e.g., "better" mapped to "good")
- Lemmatization produces valid dictionary words, which can be more meaningful and interpretable compared to stemming
- Lemmatization is more computationally expensive than stemming due to the additional linguistic knowledge required
- The choice between stemming and lemmatization depends on the specific requirements of the text analysis task, the language being processed, and the trade-off between accuracy and computational efficiency
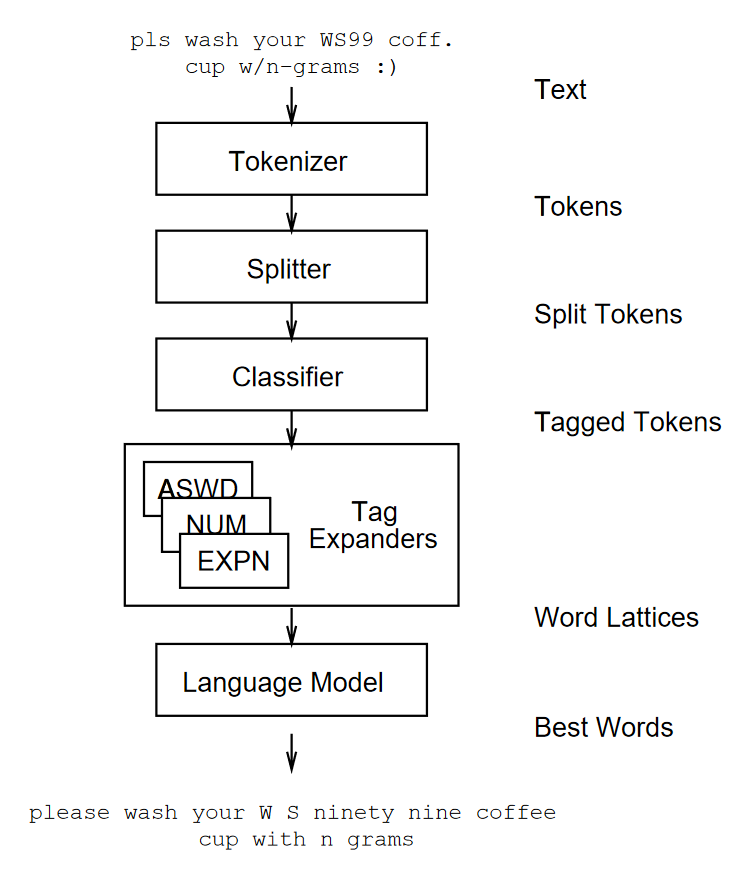
Text Tokenization and Stop Word Removal
Tokenization Techniques
- Word tokenization breaks text into individual words based on whitespace and punctuation
- It splits the text at word boundaries and removes punctuation marks (e.g., "Hello, world!" becomes ["Hello", "world"])
- Sentence tokenization splits text into separate sentences using punctuation marks and other heuristics
- It identifies sentence boundaries based on periods, question marks, exclamation points, and other indicators (e.g., "I love NLP. It's fascinating!" becomes ["I love NLP.", "It's fascinating!"])
- Subword tokenization breaks words into smaller units, such as character n-grams or byte-pair encodings
- It can be useful for handling out-of-vocabulary words or morphologically rich languages (e.g., "unhappiness" can be tokenized into ["un", "happi", "ness"])
- The choice of tokenization technique depends on the language, domain, and specific requirements of the text analysis task
Stop Word Removal
- Stop words are common words that often carry little meaning and can be removed from the text to reduce noise and improve computational efficiency
- Examples of stop words include "the," "is," "and," "in," which are frequently used but do not contribute significantly to the meaning of the text
- Stop word removal can be performed using predefined stop word lists or by calculating word frequencies and removing the most common words
- Stop word lists are language-specific and can be customized based on the domain or specific requirements of the analysis
- Removing stop words helps to focus on the most informative and meaningful words in the text
- However, in some cases, stop words may carry important information (e.g., in phrase extraction or sentiment analysis) and should be carefully considered before removal