Queues and priority queues are essential data structures that manage elements in specific orders. Queues follow the First-In-First-Out principle, while priority queues serve elements based on assigned priorities. These structures build upon the array and linked list foundations introduced earlier in the chapter.
Understanding queues and priority queues is crucial for efficient data management in various applications. From operating systems to network routers, these structures play vital roles in organizing and processing data, making them indispensable tools in a programmer's toolkit.
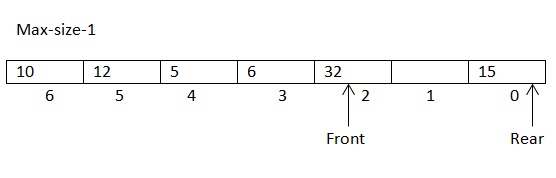
FIFO Principle and Queue Operations
Queue Fundamentals and Basic Operations
- FIFO principle governs queue behavior ensuring first element added gets removed first
- Enqueue operation adds elements to rear of queue
- Dequeue operation removes elements from front of queue
- Queue maintains front pointer for dequeue and rear pointer for enqueue
- Peek operation examines front element without removal
- Circular queues reuse empty spaces avoiding element shifting (efficient implementation)
Queue Challenges and Variations
- Queue overflow occurs when adding element to full queue
- Queue underflow happens when removing from empty queue
- Double-ended queues (deques) allow addition and removal from both ends
- Priority queues serve elements based on assigned priorities rather than arrival order
- Bounded queues have fixed maximum capacity (array-based implementations)
- Unbounded queues can grow indefinitely (linked list-based implementations)
Queue Implementations with Arrays and Linked Lists
Array-Based Queue Implementation
- Fixed-size array stores queue elements
- Front and rear pointers manage element positions
- Circular array implementation wraps around to beginning when rear reaches array end
- Dynamic array-based queues resize when initial array becomes full
- Modulo arithmetic calculates wrap-around index in circular arrays
- Array-based queues offer fast random access but may waste memory in sparse queues

Linked List-Based Queue Implementation
- Singly linked list with head and tail pointers enables efficient enqueue and dequeue
- Dynamic memory allocation allows for easier unbounded queue implementation
- Linked list nodes contain element data and next pointers
- Enqueue operation updates tail pointer and creates new node
- Dequeue operation updates head pointer and removes front node
- Linked list-based queues excel in dynamic environments but use more memory per element
Priority Queues: Concept and Applications
Priority Queue Fundamentals
- Abstract data type serving elements based on associated priorities
- Max-priority queue dequeues highest priority element first
- Min-priority queue dequeues lowest priority element first
- Insert operation adds element with specified priority
- Delete-max/min operation removes and returns highest/lowest priority element
- Peek-max/min operation returns highest/lowest priority element without removal
Priority Queue Applications
- Dijkstra's shortest path algorithm uses priority queue to select next vertex
- Huffman coding builds optimal prefix codes using priority queue
- Event-driven simulations manage future events with priority queues
- Operating systems employ priority queues for process scheduling (CPU scheduling)
- Job scheduling in print spoolers prioritizes print jobs
- Bandwidth management in network routers prioritizes data packets
Priority Queue Implementation with Heaps
Binary Heap Implementation
- Binary heaps offer efficient priority queue implementation
- Max-heaps maintain parent nodes larger than or equal to child nodes
- Min-heaps maintain parent nodes smaller than or equal to child nodes
- Heap property ensures root node has highest/lowest priority
- Array representation of binary heap uses index calculations for parent-child relationships
- Heapify operation maintains heap property after insertions or deletions
Advanced Priority Queue Implementations
- D-ary heaps generalize binary heaps with more than two children per node
- Fibonacci heaps provide improved asymptotic performance for some operations
- Pairing heaps offer simpler implementation with good amortized performance
- Bucket-based structures efficiently handle integer priorities within a known range
- Lazy deletion techniques mark elements for deletion without immediate removal
- Binomial heaps support efficient merging of priority queues
Time and Space Complexity Analysis of Queues and Priority Queues
Standard Queue Complexity Analysis
- Enqueue operation time complexity O(1) for both array and linked list implementations
- Dequeue operation time complexity O(1) for both array and linked list implementations
- Peek operation time complexity O(1) for both implementations
- Space complexity O(n) where n represents number of elements in queue
- Circular array implementation may waste one array slot to distinguish full from empty state
- Amortized analysis accounts for occasional resizing in dynamic array implementations
Priority Queue Complexity Analysis
- Binary heap insert operation time complexity O(log n)
- Binary heap delete-max/min operation time complexity O(log n)
- Binary heap peek-max/min operation time complexity O(1)
- Building heap from unordered array time complexity O(n) using bottom-up heapify
- Space complexity O(n) for binary heap-based priority queues
- Fibonacci heap offers O(1) amortized time for insert and decrease-key operations
- Pairing heap provides O(log n) amortized time for delete-min but O(1) for insert