The binomial distribution is a powerful tool for analyzing scenarios with fixed trials and two possible outcomes. It helps calculate probabilities for events like coin flips, product defects, or survey responses, using key parameters like number of trials and success probability.
Understanding the binomial distribution's characteristics, mean, and standard deviation is crucial for real-world applications. From quality control to medical research, this concept allows us to make informed decisions based on probability calculations in various fields.
Binomial Distribution
Binomial distribution probability calculations
- Binomial distribution discrete probability distribution describes number of successes in fixed number of independent trials, each with same probability of success
- Formula for binomial probability mass function:
- : total number of trials (coin flips, product tests)
- : number of successes (heads, defect-free products)
- : probability of success on each trial (fairness of coin, manufacturing process reliability)
- Calculate probability of specific number of successes by substituting values for , , and into formula
- Probability of 3 heads in 5 coin flips with fair coin:
- Formula for binomial probability mass function:
- Cumulative binomial probability calculated by summing individual probabilities for all values of up to desired number of successes
-
- Probability of 2 or fewer defective items in batch of 10 with 10% defect rate:
-
- Many calculators and software packages have built-in functions for calculating binomial probabilities (
BINOM.DISTin Excel)
Key characteristics of binomial experiments
- Binomial experiment characteristics:
- Fixed number of trials () (number of coin flips, product tests)
- Each trial independent of others (coin flips don't influence each other, products tested separately)
- Each trial has only two possible outcomes (success or failure) (heads or tails, defective or non-defective)
- Probability of success () constant for each trial (fairness of coin, manufacturing process consistency)
- Trials exhibit statistical independence
- Real-world applications of binomial distribution include:
- Quality control: Probability of certain number of defective items in batch (electronics manufacturing, food production)
- Marketing: Likelihood of specific number of customers responding to promotional offer (email campaign, product launch)
- Medical research: Probability of certain number of patients experiencing side effects from treatment (drug trials, surgical procedures)
- Finance: Probability of specific number of defaults in loan portfolio (mortgage lending, credit card issuing)

Mean and standard deviation in binomial distributions
- Mean (expected value) of binomial distribution given by:
- : total number of trials (survey respondents, product tests)
- : probability of success on each trial (response rate, defect rate)
- Expected number of defective items in batch of 100 with 5% defect rate:
- Standard deviation of binomial distribution given by:
- : total number of trials (coin flips, patients in study)
- : probability of success on each trial (heads, treatment effectiveness)
- Standard deviation of number of heads in 50 coin flips with fair coin:
- Mean and standard deviation formulas used to:
- Describe central tendency and dispersion of distribution
- Calculate z-scores and percentiles for binomial distribution
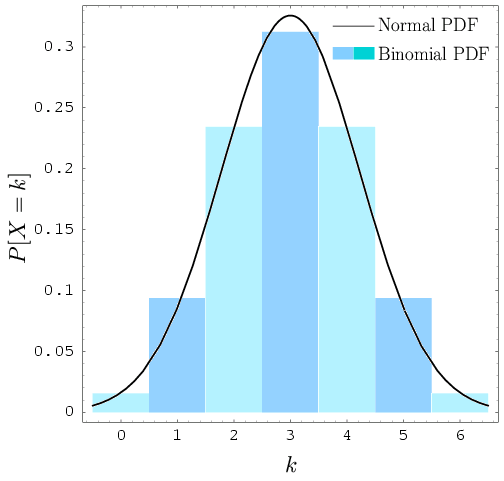
- Approximate binomial distribution with normal distribution when is large and not close to 0 or 1 (typically, when and )
Additional Concepts in Probability Theory
- Random variable: A variable whose possible values are outcomes of a random phenomenon (e.g., number of successes in a binomial experiment)
- Probability distribution: A description of the probabilities associated with all possible values of a random variable (binomial distribution is an example)
- Mutually exclusive events: Events that cannot occur simultaneously (e.g., success and failure in a single trial of a binomial experiment)
- Combinatorics: The mathematical study of counting, arrangement, and combination of objects, which is crucial in calculating binomial probabilities
- Law of large numbers: As the number of trials in a binomial experiment increases, the observed proportion of successes tends to approach the true probability of success