Content-based image retrieval revolutionizes visual data search by analyzing inherent image properties instead of relying on text annotations. This approach extracts features directly from images, enabling more accurate and efficient retrieval in large databases.
CBIR systems use computer vision techniques to analyze color, texture, and shape features, bridging the gap between low-level image data and high-level human perception. This technology powers modern image search engines, medical image analysis, and digital forensics applications.
Fundamentals of content-based retrieval
- Content-based image retrieval (CBIR) revolutionizes how we search and analyze visual data by using the inherent properties of images rather than relying on text annotations
- CBIR systems extract features directly from images, enabling more accurate and efficient retrieval in large image databases
- This approach forms a crucial component in the field of Images as Data, allowing for automated analysis and organization of visual information
Definition and purpose
- Automated process of searching and retrieving images based on their visual content rather than associated metadata or keywords
- Utilizes computer vision and image processing techniques to analyze image features (color, texture, shape)
- Aims to bridge the semantic gap between low-level image features and high-level human perception
- Enables more efficient and accurate image search in large databases (digital libraries, social media platforms)
Historical development
- Originated in the early 1990s as a response to limitations of text-based image retrieval systems
- Initial systems focused on simple color histograms and texture analysis (IBM QBIC system, 1995)
- Progressed to more sophisticated feature extraction methods (SIFT, SURF) in the early 2000s
- Recent advancements incorporate deep learning techniques for improved feature representation and matching
Advantages vs text-based retrieval
- Overcomes language barriers and inconsistencies in manual annotations
- Captures visual similarities that may be difficult to describe in words
- Reduces reliance on human-generated metadata, which can be subjective or incomplete
- Enables discovery of visually similar images even when they lack proper textual descriptions
- Supports queries based on visual examples or sketches, enhancing user interaction
Image feature extraction
- Image feature extraction forms the foundation of CBIR systems by transforming raw pixel data into meaningful representations
- This process involves analyzing various visual characteristics to create compact and discriminative descriptors
- Feature extraction techniques in CBIR directly relate to broader concepts in Images as Data, such as image representation and pattern recognition
Color features
- Histogram-based methods capture global color distribution in images
- Color moments provide statistical summaries of color channels (mean, standard deviation, skewness)
- Color correlogram represents spatial correlation of colors within specified distances
- Dominant color descriptor identifies a small set of representative colors in the image
- Color coherence vector distinguishes between coherent and incoherent pixels based on their neighborhood
Texture features
- Gray Level Co-occurrence Matrix (GLCM) measures spatial relationships between pixel intensities
- Gabor filters analyze image textures at multiple scales and orientations
- Local Binary Patterns (LBP) capture local texture patterns in a compact and rotation-invariant manner
- Wavelet transforms decompose images into multi-resolution representations for texture analysis
- Tamura features (coarseness, contrast, directionality) correspond to human visual perception of texture
Shape features
- Edge detection techniques (Canny, Sobel) identify object boundaries and structural elements
- Moment invariants provide shape descriptors that are invariant to translation, rotation, and scaling
- Fourier descriptors represent shape contours in the frequency domain
- Shape context captures the distribution of points along shape boundaries
- Region-based methods (area, perimeter, compactness) describe global shape characteristics
Local vs global features
- Global features summarize characteristics of entire images (color histograms, texture statistics)
- Local features describe specific regions or points of interest within images (SIFT, SURF keypoints)
- Global features offer computational efficiency but may lack robustness to occlusions or background changes
- Local features provide better invariance to transformations and partial occlusions
- Combination of local and global features often yields improved retrieval performance
Similarity measures
- Similarity measures quantify the degree of resemblance between image features in CBIR systems
- These metrics play a crucial role in ranking and retrieving images based on their visual content
- Understanding similarity measures connects to broader concepts in Images as Data, such as pattern matching and data clustering
Euclidean distance
- Measures the straight-line distance between two points in a multi-dimensional feature space
- Calculated as the square root of the sum of squared differences between corresponding feature values
- Formula:
- Widely used due to its simplicity and intuitive interpretation
- Sensitive to the scale of features, often requiring normalization for optimal performance
Cosine similarity
- Measures the cosine of the angle between two feature vectors in a multi-dimensional space
- Calculated as the dot product of vectors divided by the product of their magnitudes
- Formula:
- Ranges from -1 (opposite) to 1 (identical), with 0 indicating orthogonality
- Particularly useful for high-dimensional sparse data and text-based feature representations
Earth mover's distance
- Measures the minimum cost of transforming one distribution into another
- Based on the solution to the transportation problem in linear optimization
- Considers both the difference in values and the "ground distance" between bins in histograms
- Effective for comparing color and texture distributions in images
- Computationally more expensive than Euclidean distance or cosine similarity
Indexing techniques
- Indexing techniques in CBIR systems organize and structure image features to enable efficient search and retrieval
- These methods aim to reduce the computational complexity of similarity comparisons in large image databases
- Indexing approaches in CBIR relate to broader concepts in Images as Data, such as data structures and search algorithms
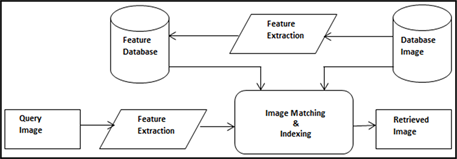
Dimensionality reduction methods
- Principal Component Analysis (PCA) identifies principal directions of variation in feature data
- Linear Discriminant Analysis (LDA) maximizes class separability for supervised dimensionality reduction
- t-SNE (t-Distributed Stochastic Neighbor Embedding) preserves local structure in high-dimensional data
- Autoencoder neural networks learn compact representations through unsupervised training
- Random projection techniques offer computationally efficient dimensionality reduction with theoretical guarantees
Tree-based indexing
- k-d trees partition feature space using alternating dimensions for efficient nearest neighbor search
- R-trees group nearby objects using minimum bounding rectangles in a hierarchical structure
- VP-trees (Vantage Point trees) partition space based on distances from selected vantage points
- M-trees optimize for disk-based storage and retrieval of metric space objects
- Quadtrees recursively subdivide 2D space into quadrants for spatial indexing of image features
Hashing techniques
- Locality Sensitive Hashing (LSH) maps similar items to the same hash buckets with high probability
- Spectral Hashing learns compact binary codes that preserve similarity relationships in the original feature space
- Iterative Quantization (ITQ) optimizes binary codes to minimize quantization error
- Kernelized Locality-Sensitive Hashing extends LSH to non-linear feature spaces using kernel functions
- Multi-index hashing combines multiple hash tables to improve search accuracy and efficiency
Query formulation
- Query formulation in CBIR systems defines how users interact with the system to express their visual information needs
- These methods bridge the gap between user intent and the underlying feature representations used by the system
- Query formulation techniques in CBIR relate to broader concepts in Images as Data, such as human-computer interaction and information retrieval
Query by example
- Users provide an example image as the query to find visually similar images in the database
- System extracts features from the query image and compares them with indexed features of database images
- Supports intuitive interaction for users who have a specific visual reference in mind
- Can be extended to multiple example images to refine search results
- Often combined with relevance feedback to improve retrieval performance iteratively
Sketch-based queries
- Users draw rough sketches or outlines to represent their desired image content
- System extracts edge and shape features from the sketch to match against database images
- Enables searches when users have a mental image but no exact example
- Challenges include handling variations in drawing styles and skill levels
- Applications include product design, criminal suspect identification, and artistic inspiration
Relevance feedback
- Interactive process where users provide feedback on the relevance of initial search results
- System refines the query representation based on user feedback to improve subsequent retrieval
- Short-term learning adjusts feature weights or query vectors for the current session
- Long-term learning accumulates user preferences over time for personalized retrieval
- Techniques include query point movement, feature re-weighting, and support vector machine-based approaches
Evaluation metrics
- Evaluation metrics in CBIR systems quantify the effectiveness and efficiency of image retrieval algorithms
- These measures provide objective criteria for comparing different CBIR approaches and assessing their performance
- Understanding evaluation metrics in CBIR connects to broader concepts in Images as Data, such as performance analysis and algorithm benchmarking
Precision and recall
- Precision measures the fraction of retrieved images that are relevant to the query
- Recall measures the fraction of relevant images in the database that are successfully retrieved
- Precision-Recall curves visualize the trade-off between precision and recall at different retrieval thresholds
- F1-score combines precision and recall into a single metric (harmonic mean)
- These metrics are sensitive to the choice of relevance threshold and the size of the retrieval set
Mean average precision
- Calculates the average precision values at different recall levels for a set of queries
- Provides a single-value summary of the precision-recall curve
- Formula:
- Emphasizes retrieving relevant items earlier in the ranked list
- Widely used in information retrieval and CBIR benchmarking (TREC, ImageCLEF)
NDCG and other measures
- Normalized Discounted Cumulative Gain (NDCG) measures the usefulness of a ranking based on graded relevance
- Accounts for the position of relevant items in the ranked list, with higher positions given more weight
- Cumulative Match Characteristic (CMC) curve evaluates performance in identification tasks
- Average Normalized Modified Retrieval Rank (ANMRR) assesses both retrieval accuracy and ranking quality
- User-centric metrics (task completion time, user satisfaction) provide insights into real-world system usability
Applications and use cases
- CBIR systems find applications across various domains where visual information retrieval and analysis are crucial
- These use cases demonstrate the practical impact of CBIR techniques in solving real-world problems
- Exploring applications of CBIR connects to broader themes in Images as Data, such as computer vision and data-driven decision making
Image search engines
- Web-scale image search platforms (Google Images, Bing Visual Search) incorporate CBIR techniques
- Reverse image search allows users to find similar or identical images across the web
- Visual product search in e-commerce platforms enables users to find items based on appearance
- Stock photo libraries use CBIR to help users find relevant images for their projects
- Social media platforms employ CBIR for content moderation and duplicate detection

Medical image analysis
- Content-based retrieval of medical images aids in diagnosis and treatment planning
- Radiologists use CBIR to find similar cases in large archives of medical images (X-rays, MRIs, CT scans)
- Pathology image analysis benefits from CBIR for identifying similar tissue samples
- Dermatology applications use CBIR to compare skin lesions and assist in melanoma detection
- CBIR supports computer-aided diagnosis systems by retrieving relevant historical cases
Digital forensics
- Law enforcement agencies use CBIR to search large databases of crime scene photos and evidence
- Face recognition systems employ CBIR techniques for suspect identification and missing person searches
- Tattoo matching systems assist in identifying individuals based on distinctive body art
- CBIR aids in detecting and tracking illegal content (child exploitation material) across online platforms
- Image authentication and tampering detection rely on CBIR methods to identify manipulated images
Challenges and limitations
- CBIR systems face various challenges that impact their effectiveness and adoption in real-world scenarios
- Understanding these limitations is crucial for developing improved CBIR techniques and managing user expectations
- Addressing challenges in CBIR relates to broader issues in Images as Data, such as data representation and algorithmic fairness
Semantic gap
- Discrepancy between low-level visual features and high-level semantic concepts understood by humans
- Machines struggle to interpret abstract or context-dependent visual information (emotions, symbolism)
- Bridging the semantic gap requires integrating domain knowledge and contextual information
- Approaches include ontology-based methods, machine learning techniques, and multimodal fusion
- Remains an active area of research in CBIR and computer vision
Scalability issues
- Large-scale image databases pose challenges for indexing and real-time retrieval
- High-dimensional feature spaces suffer from the "curse of dimensionality"
- Computational complexity increases with database size and feature dimensionality
- Distributed computing and parallel processing techniques address scalability challenges
- Trade-offs between retrieval accuracy and computational efficiency must be carefully managed
Privacy concerns
- CBIR systems may inadvertently reveal sensitive information in images (faces, locations, activities)
- Reverse image search can be used to identify individuals or track their online presence
- Data collection for training CBIR models raises questions about user consent and data ownership
- Privacy-preserving CBIR techniques (secure multi-party computation, homomorphic encryption) are emerging
- Ethical considerations in CBIR deployment include transparency, fairness, and user control
Advanced techniques
- Advanced techniques in CBIR leverage recent developments in machine learning and computer vision
- These methods aim to address limitations of traditional CBIR approaches and improve retrieval performance
- Exploring advanced CBIR techniques connects to cutting-edge research in Images as Data and artificial intelligence
Deep learning in CBIR
- Convolutional Neural Networks (CNNs) learn hierarchical feature representations directly from image data
- Transfer learning utilizes pre-trained CNN models (VGG, ResNet) for efficient feature extraction
- Siamese networks learn similarity metrics between image pairs for improved retrieval
- Generative Adversarial Networks (GANs) synthesize images for data augmentation and query expansion
- Attention mechanisms in deep learning models focus on salient image regions for more effective retrieval
Multimodal retrieval
- Combines visual features with other modalities (text, audio, metadata) for more comprehensive retrieval
- Cross-modal learning techniques align feature spaces of different modalities
- Joint embedding models learn shared representations for multiple modalities
- Fusion strategies (early fusion, late fusion, hybrid approaches) integrate information from different sources
- Applications include retrieving images based on textual descriptions or finding relevant captions for images
Cross-modal retrieval
- Enables queries in one modality to retrieve results in another modality (text-to-image, image-to-text)
- Zero-shot learning approaches generalize to unseen classes using semantic embeddings
- Visual-semantic embedding models align visual and textual feature spaces
- Cycle-consistent adversarial networks learn mappings between unpaired data in different modalities
- Applications include image captioning, visual question answering, and text-based image generation
Future directions
- Future directions in CBIR research and development aim to address current limitations and explore new possibilities
- These trends reflect the evolving landscape of visual data analysis and retrieval technologies
- Exploring future directions in CBIR connects to broader trends in Images as Data, such as artificial intelligence and human-centered computing
Integration with AI
- Incorporation of explainable AI techniques to provide interpretable retrieval results
- Development of self-supervised learning approaches for more efficient feature learning
- Integration of natural language processing for more intuitive and flexible query formulation
- Exploration of reinforcement learning for adaptive and personalized retrieval strategies
- Investigation of federated learning techniques for privacy-preserving CBIR model training
Real-time retrieval systems
- Advancements in hardware acceleration (GPUs, TPUs) enable faster feature extraction and matching
- Development of approximate nearest neighbor search algorithms for sub-linear time retrieval
- Exploration of edge computing solutions for low-latency CBIR applications (mobile devices, IoT)
- Implementation of progressive retrieval techniques for improved user experience
- Integration of streaming data processing for real-time updates to image databases
Personalized image retrieval
- Development of user modeling techniques to capture individual preferences and search patterns
- Exploration of context-aware retrieval systems that adapt to user's current situation and needs
- Investigation of multi-task learning approaches to jointly optimize for relevance and diversity
- Implementation of interactive visualization techniques for more intuitive exploration of search results
- Integration of social network information for collaborative and community-based image retrieval