ARMA models blend past values and errors to predict future outcomes in time series data. They combine autoregressive (AR) and moving average (MA) components, capturing both historical trends and recent fluctuations.
Understanding ARMA models is crucial for forecasting stationary time series. By grasping their structure, characteristics, and forecasting process, you'll be better equipped to analyze and predict patterns in various fields, from finance to environmental studies.
ARMA model foundations
Composition and structure of ARMA models
- ARMA models combine autoregressive (AR) and moving average (MA) components capturing both the dependence on past values and the influence of past forecast errors
- The AR component represents the relationship between an observation and a specified number of lagged observations ()
- The MA component represents the error of the model as a combination of previous error terms with a specified number of lags ()
- ARMA models are denoted as ARMA(,) where is the order of the autoregressive term and is the order of the moving average term
- The general form of an ARMA(,) model is:
- is the time series value at time
- is a constant term
- and are model parameters
- is white noise (random error) at time
Stationarity assumption in ARMA models
- ARMA models assume the time series is stationary meaning its statistical properties (mean, variance, autocovariance) do not change over time
- Stationarity is crucial for the model to capture the underlying patterns and relationships in the data accurately
- Non-stationary time series can lead to spurious relationships and unreliable forecasts
- Stationarity can be assessed using visual inspection (time series plot), statistical tests (Augmented Dickey-Fuller, KPSS), or examining ACF and PACF plots
- If the time series is non-stationary, transformations such as differencing or detrending can be applied to achieve stationarity before fitting an ARMA model
ARMA model characteristics
Autoregressive (AR) component
- The AR component captures the linear dependence between an observation and its past values
- The order determines the number of lagged observations included in the model
- Higher values of indicate a stronger dependence on past observations
- The AR component is represented by the term in the ARMA equation
- The parameters determine the weights assigned to the lagged observations

Moving average (MA) component
- The MA component represents the error of the model as a linear combination of past forecast errors
- The order determines the number of lagged errors included in the model
- Higher values of indicate a stronger influence of past forecast errors
- The MA component is represented by the term in the ARMA equation
- The parameters determine the weights assigned to the lagged errors
Additional components and parameters
- The constant term in the ARMA model represents the mean of the time series if it is non-zero
- The white noise term represents the random error or innovation at time assumed to be independently and identically distributed with a mean of zero and constant variance
- The parameters and are estimated using methods such as maximum likelihood estimation or least squares to minimize the difference between the observed and predicted values
ARMA model forecasting
Model development process
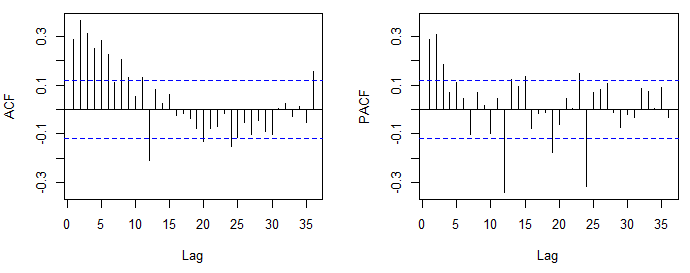
- Determine the appropriate orders ( and ) using tools such as the autocorrelation function (ACF) and partial autocorrelation function (PACF)
- ACF measures the correlation between observations at different lags
- PACF measures the correlation between observations at different lags while controlling for the effects of intermediate lags
- Estimate the model parameters ( and ) using suitable methods like maximum likelihood estimation or least squares ensuring the estimated parameters are statistically significant
- Assess the model's goodness of fit using diagnostic tests such as the Ljung-Box test for residual autocorrelation and the Akaike Information Criterion (AIC) or Bayesian Information Criterion (BIC) for model selection
Interpretation and forecasting
- Interpret the estimated parameters to understand the influence of past observations and errors on the current value of the time series
- Positive values indicate a positive relationship between the current observation and the -th lagged observation
- Negative values indicate a negative relationship between the current observation and the -th lagged error
- Use the developed ARMA model to generate forecasts for future time periods
- Assess the accuracy of these forecasts using appropriate evaluation metrics such as mean squared error (MSE) or mean absolute percentage error (MAPE)
- MSE measures the average squared difference between the observed and predicted values
- MAPE measures the average absolute percentage difference between the observed and predicted values
Stationarity vs Invertibility in ARMA models
Stationarity requirement
- ARMA models require the time series to be stationary meaning its statistical properties (mean, variance, autocovariance) do not change over time
- Stationarity ensures the model captures the underlying patterns and relationships in the data accurately
- Non-stationary time series can lead to spurious relationships and unreliable forecasts
- If the time series is non-stationary, transformations such as differencing or detrending can be applied to achieve stationarity before fitting an ARMA model
- Differencing involves computing the differences between consecutive observations to remove trends
- Detrending involves removing deterministic trends (linear, quadratic) from the time series
Invertibility requirement
- Invertibility is a requirement for the MA component of the ARMA model ensuring the model can be expressed as an infinite sum of past observations
- The invertibility condition is satisfied when the absolute values of the roots of the MA characteristic equation lie outside the unit circle
- MA characteristic equation:
- The roots of this equation should have absolute values greater than 1
- Non-invertible ARMA models can lead to identifiability issues and unreliable parameter estimates making it crucial to ensure invertibility before interpreting and using the model for forecasting
- Invertibility can be checked by examining the roots of the MA characteristic equation or by assessing the model's residuals for independence and normality