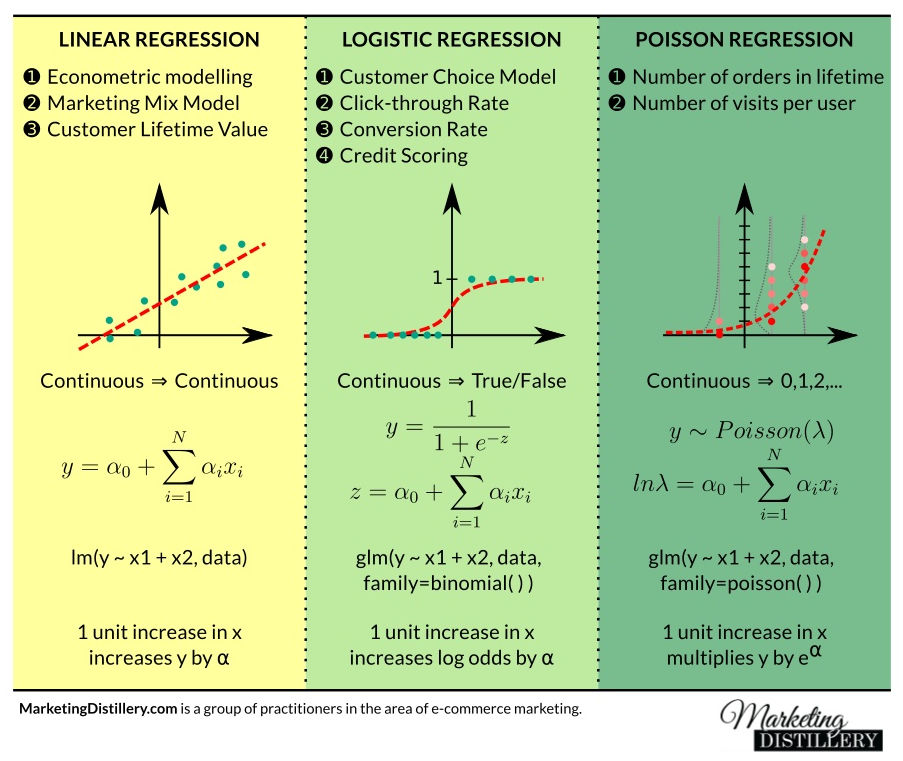
Polynomial regression takes linear regression to the next level, modeling complex relationships between variables as curved lines. It's a powerful tool for engineers dealing with nonlinear data that simple straight lines can't capture.
This method shines in engineering applications, from predicting material behavior to optimizing machine performance. By fitting curves to data, polynomial regression helps make better predictions and decisions in various engineering fields.
Polynomial Regression in Engineering
Concept and Applications
- Polynomial regression models the relationship between independent and dependent variables as an nth degree polynomial function
- Used when the relationship between variables is nonlinear and cannot be adequately captured by a simple linear regression model
- Applied in engineering contexts to model complex relationships
- Behavior of materials under different conditions
- Performance of machines or systems
- Optimization of processes
- Employed for curve fitting, data interpolation, and extrapolation in various engineering domains (mechanical, electrical, chemical, civil engineering)
Advantages and Uses
- Captures nonlinear patterns that cannot be adequately represented by a simple linear model
- Models complex behaviors in engineering systems
- Performance of a machine under varying operating conditions
- Efficiency of a process at different parameter settings
- Response of a material to different stress levels
- Provides more accurate predictions and better fits the observed data compared to linear regression models
- Aids in optimizing engineering designs, controlling processes, and making data-driven decisions
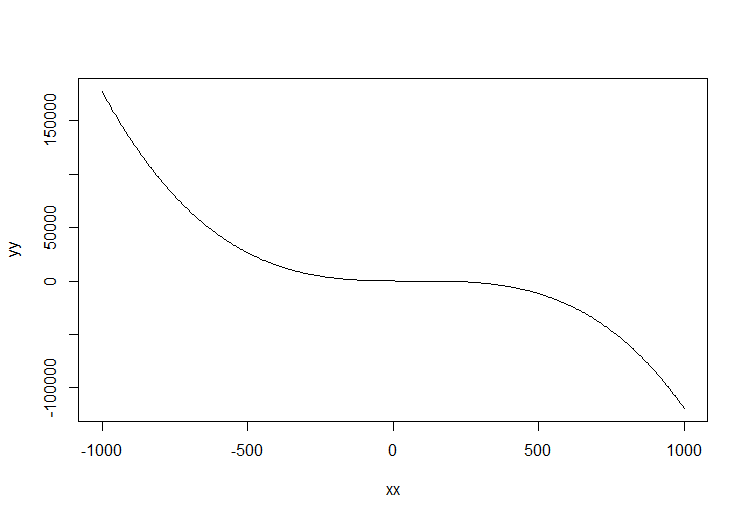
Polynomial Model Degree Selection
Factors Influencing Degree Choice
- The degree determines the complexity and flexibility of the regression curve
- Higher degree allows for more complex relationships but may lead to overfitting
- Choice depends on the nature of the data and underlying physical or engineering principles governing the relationship between variables
- Visual inspection of data points plotted on a scatter plot provides an initial indication of appropriate degree
- Clear curvature or multiple bends suggest a higher degree polynomial may be necessary
- Domain knowledge and understanding of the engineering system being modeled can guide the selection
- Some relationships may have known theoretical foundations suggesting a specific degree
Model Selection Techniques
- Principle of parsimony (Occam's razor) suggests choosing the simplest model that adequately fits the data
- Select the lowest degree polynomial that captures essential features without overfitting
- Cross-validation techniques (k-fold cross-validation) assess performance of polynomial models with different degrees
- Helps select the optimal degree balancing fit and generalization
- Consider the range and distribution of independent variables to ensure the model is not extrapolating beyond observed data
- Validate polynomial regression models using appropriate techniques
- Cross-validation or holdout validation assess performance on unseen data and guard against overfitting
Coefficient Interpretation in Polynomial Regression
Understanding Coefficients
- Coefficients represent weights assigned to each term of the polynomial function
- Interpretation depends on the degree of the polynomial and scale of the variables
- Constant term (intercept) represents the predicted value of the dependent variable when all independent variables are zero
- Coefficient of the linear term indicates the change in the dependent variable for a one-unit increase in the independent variable, assuming all other terms are held constant
- Coefficients of higher-order terms (quadratic, cubic) represent the impact of corresponding powers of the independent variable on the dependent variable
- Capture nonlinear effects in the relationship
Assessing Coefficient Significance
- Significance of coefficients assessed using hypothesis testing and p-values
- Low p-value (typically < 0.05) suggests coefficient is statistically significant and has a meaningful impact on the dependent variable
- Magnitude and sign of coefficients provide insights into direction and strength of the relationship
- Positive coefficients indicate a positive relationship
- Negative coefficients indicate an inverse relationship
- Choice of polynomial degree and inclusion of interaction terms based on domain knowledge, statistical significance, and model performance metrics (mean squared error, R-squared)
Polynomial Regression for Nonlinear Relationships
Capturing Nonlinearity
- Particularly useful when the relationship between variables exhibits a nonlinear pattern
- Captures complex behaviors in engineering systems
- Performance of a machine under varying operating conditions
- Efficiency of a process at different parameter settings
- Response of a material to different stress levels
- Provides more accurate predictions and better fits the observed data compared to linear regression models
Application and Considerations
- Improved predictive accuracy aids in optimizing engineering designs, controlling processes, and making data-driven decisions
- Consider the range and distribution of independent variables to ensure the model is not extrapolating beyond observed data
- Validate polynomial regression models using appropriate techniques
- Cross-validation or holdout validation assess performance on unseen data and guard against overfitting
- Choice of polynomial degree and inclusion of interaction terms based on domain knowledge, statistical significance, and model performance metrics (mean squared error, R-squared)