LSTMs revolutionize sequence processing in deep learning. Their unique architecture, with input, forget, and output gates, allows for long-term memory retention. This makes them ideal for tasks like machine translation, speech recognition, and text summarization.
Implementing LSTM models involves careful data preprocessing, encoder-decoder structures, and training strategies. Evaluating their performance requires specialized metrics and error analysis to understand their strengths and limitations in handling complex language tasks.
LSTM Architecture and Applications
Architecture of LSTM sequence-to-sequence models
- Sequence-to-sequence (seq2seq) model structure transforms input sequences into output sequences using encoder network processes input and decoder network generates output
- LSTM cell components work together to control information flow input gate regulates new information, forget gate discards irrelevant data, output gate determines cell output, cell state maintains long-term memory
- Information flow in LSTM networks maintains long-term dependencies through carefully regulated cell state, allowing smooth gradient flow during backpropagation
- Encoder-decoder mechanism uses context vector to summarize input sequence, attention mechanism allows decoder to focus on relevant parts of input (machine translation, image captioning)
Applications of LSTMs in language tasks
- Machine translation encodes source language, decodes into target language, handles variable-length inputs/outputs (English to French, Chinese to Spanish)
- Speech recognition extracts audio features, recognizes phonemes, integrates language modeling to convert speech to text (voice assistants, transcription services)
- Text summarization uses extractive methods to select important sentences or abstractive methods to generate new text, handles long input sequences (news articles, scientific papers)
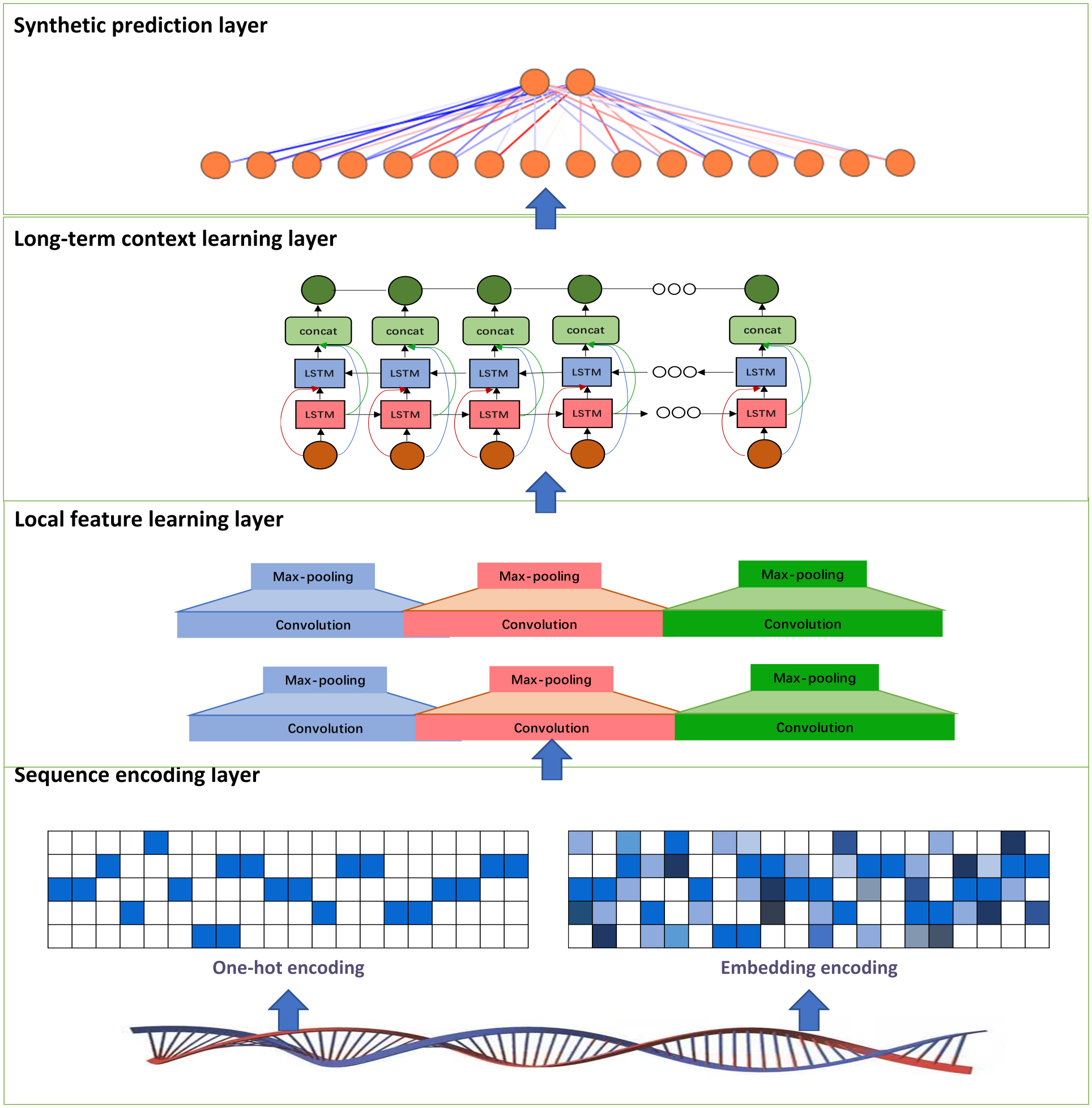
Implementation of encoder-decoder LSTM models
- Data preprocessing involves tokenization to break text into units, vocabulary creation to map tokens to indices, sequence padding to ensure uniform length
- Encoder implementation uses embedding layer to represent tokens, LSTM layers to process sequence, final hidden state serves as context for decoder
- Decoder implementation initializes with encoder's final state, uses teacher forcing during training, employs beam search during inference for better results
- Training process selects appropriate loss function (cross-entropy), chooses optimizer (Adam, RMSprop), processes data in batches for efficiency
Performance assessment of LSTM models
- Evaluation metrics include BLEU score for translation quality, Word Error Rate (WER) for speech recognition accuracy, ROUGE score for summarization effectiveness
- Model comparison analyzes LSTM vs. GRU performance, assesses impact of attention mechanism in seq2seq models
- Performance analysis examines handling of long sequences, addresses rare word problem, identifies overfitting/underfitting issues
- Error analysis investigates common failure modes (repetition, hallucination), identifies model limitations (context understanding, world knowledge)