Convolutional Neural Networks (CNNs) mimic human visual processing by building progressively complex representations. From detecting basic visual elements to assembling complex object structures, CNNs use hierarchical feature representations to process images effectively.
CNNs employ convolutional layers, pooling layers, and activation functions to learn and extract features. This hierarchical approach allows for the detection of local patterns through receptive fields and the development of increasingly abstract representations in deeper layers.
Hierarchical Representations in CNNs
Hierarchical feature representations in CNNs
- Feature hierarchy in CNNs mimics human visual processing builds progressively complex representations
- Low-level features (early layers) detect basic visual elements (edges, colors, simple textures)
- Mid-level features (intermediate layers) combine low-level features form shapes and object parts
- High-level features (deeper layers) assemble complex object structures and scene compositions
- Convolutional layers apply learnable filters detect specific patterns each layer builds upon previous layer's features
- Pooling layers reduce spatial dimensions increase invariance to small translations (max pooling, average pooling)
- Activation functions (ReLU, sigmoid) introduce non-linearity enable learning of complex patterns

Receptive fields for local patterns
- Receptive field refers to region in input space affecting particular CNN feature grows larger in deeper layers
- Local connectivity limits each neuron's connections to small region of previous layer preserves spatial relationships
- Receptive field size increases in deeper layers influenced by filter size, stride, and pooling operations
- Enables detection of local features at various scales (textures, object parts)
- Overlapping receptive fields allow feature detection at different locations
- Field of view expands with network depth captures larger context for global understanding
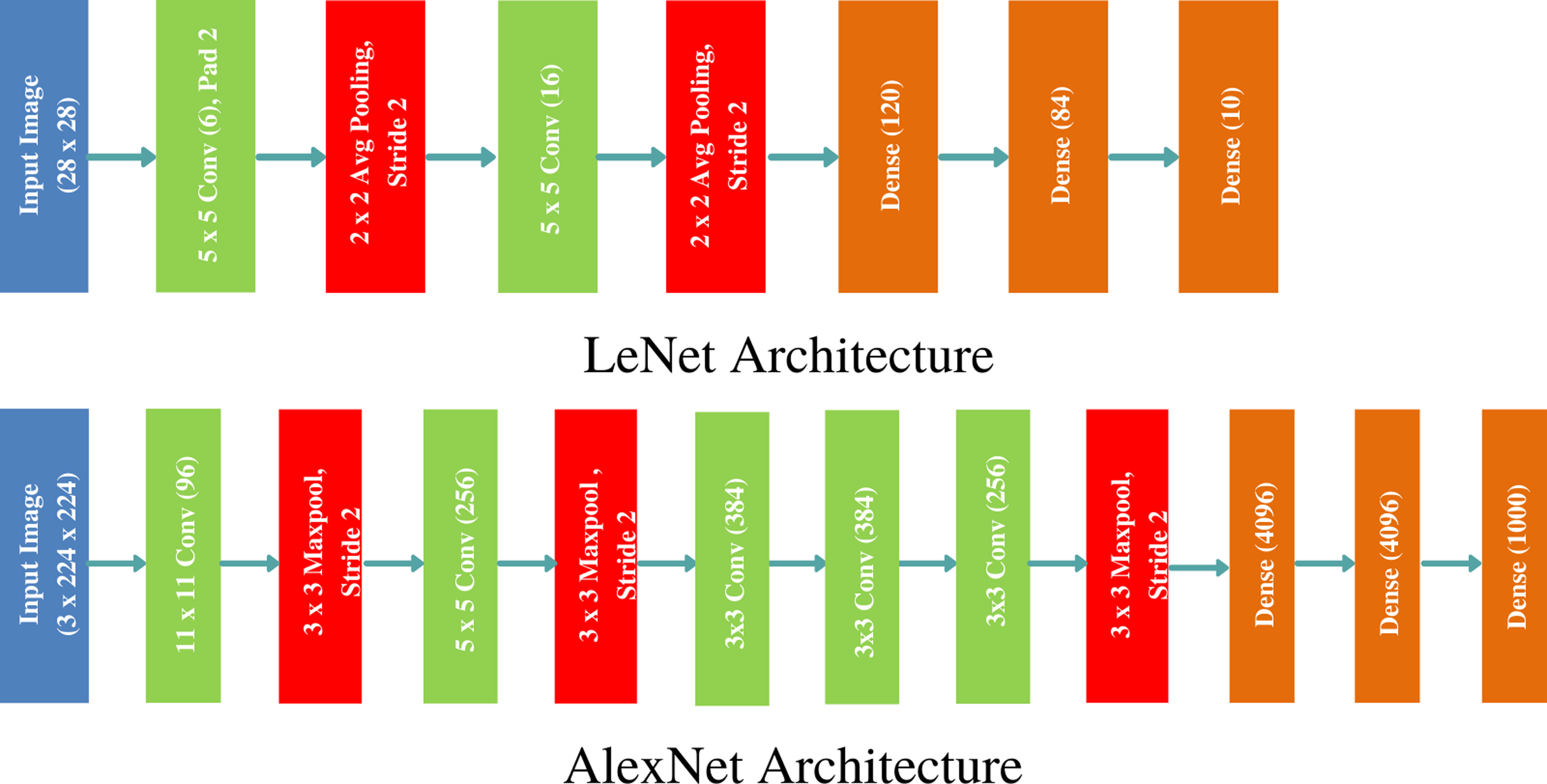
Deeper layers for complex features
- Increasing abstraction shallow layers detect simple features (edges, colors) deep layers capture complex composite features (faces, vehicles)
- Feature composition deeper layers combine lower-level features create more abstract representations
- Global context larger receptive fields in deeper layers capture relationships between distant parts of input (scene layout)
- Invariance properties deeper layers become more robust to input transformations (rotation, scale)
- Visualization techniques aid understanding (feature maps, activation maximization)
- Transfer learning deeper layers more task-specific earlier layers more general and transferable
Feature extraction importance in vision
- Automatic feature learning CNNs learn relevant features without manual engineering adapt to various tasks and datasets
- Task-specific extraction tailored for different vision tasks (classification, detection, segmentation, recognition)
- Feature reuse pre-trained models serve as feature extractors fine-tuned for specific tasks
- Robustness to variations handles changes in illumination, pose, and occlusions
- Dimensionality reduction creates compact representations of high-dimensional image data
- Interpretability analysis of learned features improves model understanding
- Performance improvements increases accuracy in vision tasks enables efficient processing of large-scale datasets