Transformer models revolutionized sequence processing with their encoder-decoder architecture and attention mechanism. They excel at capturing long-range dependencies and enable parallel processing, outperforming traditional RNNs in various natural language tasks.
Key components include input embedding, positional encoding, multi-head attention, and feed-forward networks. The architecture's power lies in its self-attention mechanism, residual connections, and layer normalization, which together enhance performance and stability in deep networks.
Transformer Architecture Overview
Architecture of transformer model
- Transformer model structure employs encoder-decoder architecture with attention mechanism as core component enabling efficient processing of sequential data
- Key components include input embedding converting tokens to vectors, positional encoding adding sequence order information, multi-head attention capturing contextual relationships, feed-forward neural networks processing transformed representations, layer normalization stabilizing activations, and residual connections facilitating gradient flow
- Advantages over RNNs include parallel processing of input sequences and ability to capture long-range dependencies without recurrence (LSTM, GRU)
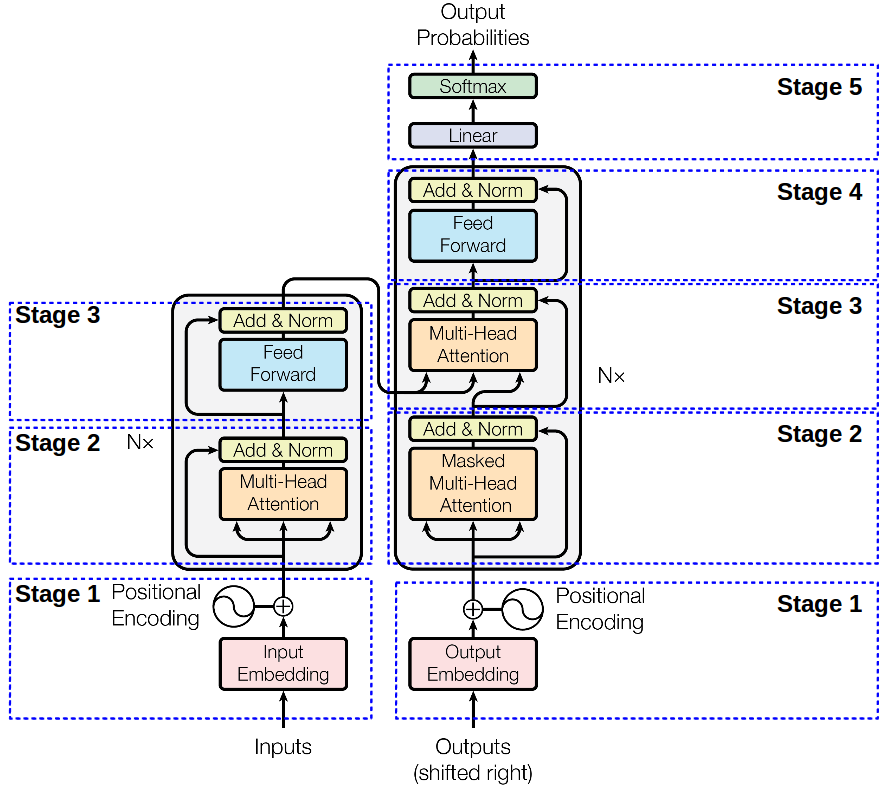
Implementation of encoder-decoder blocks
- Encoder block structure consists of multi-head self-attention layer processing input sequences and feed-forward neural network further transforming representations
- Decoder block structure incorporates masked multi-head self-attention layer preventing leftward information flow, multi-head attention layer for encoder-decoder attention, and feed-forward neural network for final processing
- Self-attention mechanism utilizes query, key, and value matrices to compute relevance scores and weighted sum of values
- Multi-head attention applies parallel attention heads, concatenating and linearly transforming outputs for richer representations
- Position-wise feed-forward network applies two linear transformations with ReLU activation enhancing model's capacity to capture complex patterns

Role of residual connections
- Residual connections create skip connections between layers mitigating vanishing gradient problem in deep networks
- Layer normalization normalizes inputs across features reducing internal covariate shift and stabilizing training process
- Combined effect of residual connections and layer normalization leads to faster convergence, improved model performance, and enhanced stability in deep transformer architectures
Applications in sequence-to-sequence tasks
- Machine translation encodes source language and decodes target language using beam search for output generation (English to French)
- Text summarization performs extractive summarization by selecting key sentences or abstractive summarization by generating new concise text
- Other applications include question answering systems, text classification tasks, and named entity recognition in natural language processing
- Fine-tuning pre-trained transformer models enables transfer learning for specific tasks and adaptation to domain-specific data (BERT, GPT)