Odds ratios are a key tool in logistic regression, helping us understand how variables affect the likelihood of an outcome. They show the change in odds when a predictor increases by one unit, making it easier to compare different factors' impacts.
Confidence intervals for odds ratios give us a range of possible true values, helping assess the precision and significance of our findings. By using odds ratios and their confidence intervals, we can rank predictors, examine interactions, and make practical decisions based on our analysis.
Odds Ratios in Logistic Regression
Interpreting Odds Ratios
- Odds ratios represent the change in odds of the outcome for a one-unit increase in the predictor variable, holding other variables constant
- In logistic regression, the odds ratio equals the exponentiated coefficient (e^β) for a given predictor variable
- Odds ratio greater than 1 indicates an increased likelihood of the outcome, while less than 1 indicates a decreased likelihood
- Interpret odds ratios as percentage changes in odds by subtracting 1 from the odds ratio and multiplying by 100
- Example: Odds ratio of 1.5 means a 50% increase in odds
- Example: Odds ratio of 0.75 means a 25% decrease in odds
- Null value for an odds ratio equals 1, indicating no association between the predictor and the outcome
- Odds ratios have multiplicative properties, allowing combination of effects from multiple predictors by multiplying their individual odds ratios
- Example: If predictor A has an odds ratio of 1.5 and predictor B has an odds ratio of 2, their combined effect would be 1.5 * 2 = 3
Mathematical Properties of Odds Ratios
- Calculate odds ratios using the formula:
- β represents the logistic regression coefficient
- Odds ratios range from 0 to positive infinity
- OR = 1 indicates no effect
- 0 < OR < 1 indicates a negative association
- OR > 1 indicates a positive association
- Logarithm of odds ratios produces the logistic regression coefficient
- Inverse relationship between odds ratios for binary predictors
- Example: If the odds ratio for males compared to females is 2, the odds ratio for females compared to males is 1/2
Confidence Intervals for Odds Ratios
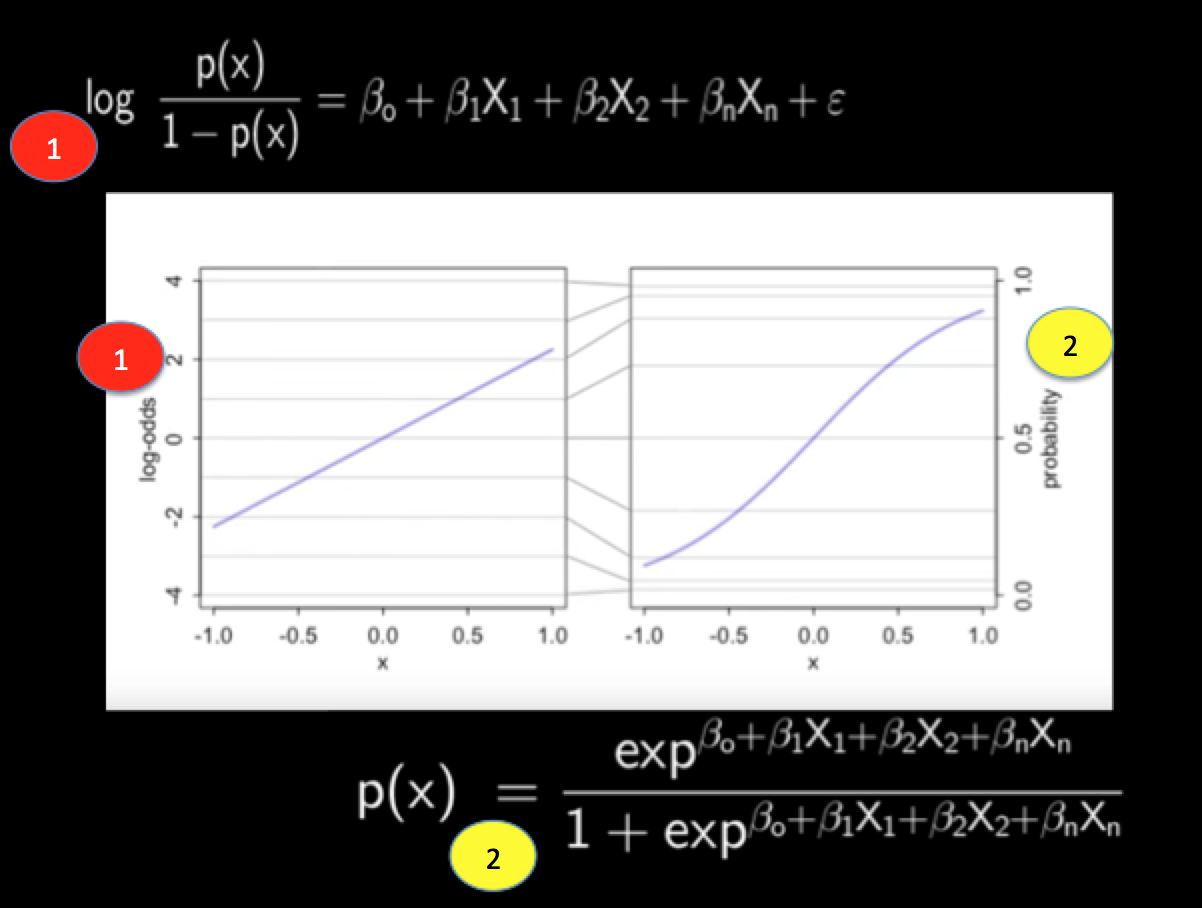
Calculating Confidence Intervals
- Confidence intervals for odds ratios provide a range of plausible values for the true population odds ratio
- Formula for calculating the 95% confidence interval for an odds ratio:
CI_{95\\%} = e^{(β ± 1.96 * SE(β))}
- β represents the logistic regression coefficient
- SE(β) denotes its standard error
- Lower bound of the confidence interval:
- Upper bound of the confidence interval:
- Wider confidence intervals indicate less precision in the estimate, while narrower intervals suggest more precise estimates
- Example: CI of (1.2, 1.8) is more precise than CI of (0.9, 2.5)
Interpreting Confidence Intervals
- Confidence interval including 1 suggests the association between the predictor and outcome lacks statistical significance at the chosen level
- Example: CI of (0.8, 1.2) includes 1, indicating a non-significant association
- Interpret confidence intervals considering both statistical significance and practical importance
- Example: CI of (1.01, 1.05) might be statistically significant but have limited practical importance
- Use confidence intervals to compare the strength of associations between different predictors and the outcome
- Example: Predictor A with CI (1.5, 2.5) shows a stronger association than Predictor B with CI (1.1, 1.3)
- Narrower confidence intervals generally indicate more reliable estimates
- Example: CI of (1.8, 2.2) provides more confidence in the estimate than CI of (1.5, 2.5)
Quantifying Associations with Odds Ratios
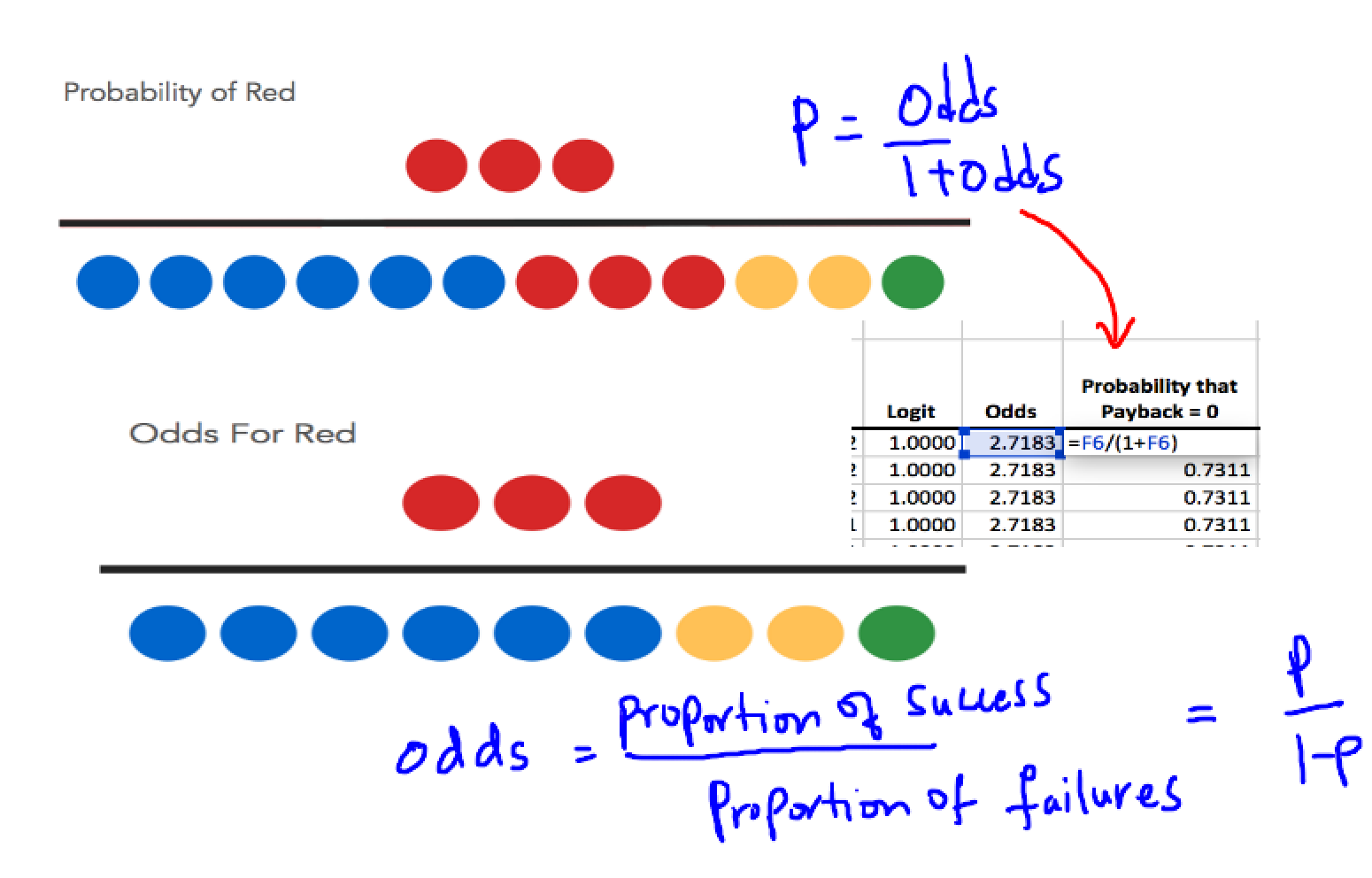
Comparing Predictor Importance
- Odds ratios allow comparison of the relative importance of different predictors in a logistic regression model
- Magnitude of the odds ratio indicates the strength of the association between a predictor and the binary outcome
- Rank predictors based on their impact on the outcome, with larger deviations from 1 indicating stronger associations
- Example: OR of 3.5 for smoking vs. OR of 1.2 for age suggests smoking has a stronger association with lung cancer
- For continuous predictors, the odds ratio represents the change in odds for a one-unit increase in the predictor
- Example: OR of 1.05 for age means 5% increase in odds for each year increase in age
- For categorical predictors, the odds ratio compares the odds of the outcome for one category relative to a reference category
- Example: OR of 2.5 for college graduates compared to high school graduates in predicting job success
Examining Interactions
- Investigate interactions between predictors by including interaction terms in the model and interpreting their corresponding odds ratios
- Interaction odds ratio represents how the effect of one predictor changes across levels of another predictor
- Example: OR of 1.5 for the interaction between gender and treatment indicates the treatment effect differs by gender
- Interpret main effects and interaction effects together to understand the full relationship between predictors and the outcome
- Visualize interactions using plots of predicted probabilities or odds ratios across different levels of interacting variables
- Example: Plot treatment effect separately for males and females to illustrate gender interaction
Practical Significance of Odds Ratios
Communicating Odds Ratios
- Translate odds ratios into easily understandable language, such as "X times more likely" or "Y% increase in odds"
- Example: OR of 2.5 for smoking translates to "Smokers are 2.5 times more likely to develop lung cancer"
- Provide context for the magnitude of odds ratios by comparing them to other known risk factors or benchmarks in the field
- Example: Compare the OR for a new drug to the OR of existing treatments
- Use visual aids, such as forest plots or odds ratio charts, to display odds ratios and their confidence intervals for multiple predictors
- Example: Create a forest plot showing ORs and CIs for age, gender, and smoking status in predicting heart disease
Interpreting Practical Implications
- Explain limitations of odds ratios, including their inability to provide information about absolute risk or causality
- Discuss practical implications of the odds ratios in terms of decision-making, resource allocation, or intervention strategies
- Example: An OR of 3 for a modifiable risk factor might suggest prioritizing interventions targeting that factor
- Address potential confounding factors and emphasize the importance of considering other variables when interpreting odds ratios
- Consider the baseline risk when interpreting the practical significance of an odds ratio
- Example: An OR of 2 for a rare outcome might have less practical importance than an OR of 1.5 for a common outcome
- Evaluate the cost-effectiveness and feasibility of interventions based on the magnitude of odds ratios
- Example: A large OR for an easily modifiable risk factor might suggest a high-impact, low-cost intervention