Background subtraction is a key technique in computer vision that isolates moving objects from static scenes. It's used in surveillance, traffic monitoring, and human-computer interaction, serving as a crucial preprocessing step for many applications.
This method compares video frames to a reference model, creating binary masks of foreground objects. It faces challenges like dynamic backgrounds, lighting changes, and camera movements. Various algorithms tackle these issues, balancing accuracy and efficiency for real-time performance.
Fundamentals of background subtraction
- Background subtraction plays a crucial role in computer vision and image processing by isolating moving objects from static scenes
- Serves as a fundamental preprocessing step for various applications including surveillance, traffic monitoring, and human-computer interaction
- Involves comparing each video frame against a reference or background model to identify regions of interest
Definition and purpose
- Technique used to separate foreground objects from the background in a sequence of images or video frames
- Aims to create a binary mask where pixels corresponding to moving objects are labeled as foreground
- Enables efficient object detection and tracking by focusing computational resources on regions of interest
Applications in computer vision
- Video surveillance systems utilize background subtraction to detect intruders or suspicious activities
- Traffic monitoring applications employ this technique to track vehicles and analyze traffic flow patterns
- Human-computer interaction systems use background subtraction for gesture recognition and motion-based interfaces
- Medical imaging benefits from this method to detect changes in sequential scans (MRI, CT)
Challenges in background subtraction
- Handling dynamic backgrounds with moving elements (trees swaying, water rippling)
- Adapting to gradual illumination changes throughout the day
- Dealing with sudden lighting variations (clouds passing, lights turning on/off)
- Distinguishing between genuine foreground objects and background motion
- Managing camera jitter or small movements that can affect the background model
Static vs dynamic backgrounds
- Background subtraction techniques must account for different types of scenes encountered in real-world applications
- Static backgrounds provide a more straightforward scenario for object detection and tracking
- Dynamic backgrounds introduce additional complexity and require more sophisticated algorithms
Characteristics of static backgrounds
- Remain relatively constant over time with minimal changes in pixel values
- Typically found in indoor environments or controlled settings (laboratory, manufacturing floor)
- Allow for simpler background modeling techniques (frame averaging, median filtering)
- Provide higher accuracy in foreground detection due to reduced noise and false positives
Challenges with dynamic backgrounds
- Contain non-stationary elements that exhibit regular or irregular motion (fountains, escalators)
- Require algorithms capable of distinguishing between background motion and genuine foreground objects
- Increase the likelihood of false positives in foreground detection
- Necessitate more frequent updates to the background model to maintain accuracy
Adaptive background modeling
- Dynamically updates the background model to account for changes in the scene over time
- Employs techniques like exponential moving average or running Gaussian average to adapt to gradual changes
- Utilizes multi-modal approaches (Mixture of Gaussians) to handle backgrounds with multiple states
- Implements selective update strategies to prevent foreground objects from being absorbed into the background
Common background subtraction techniques
- Various algorithms have been developed to address the challenges of background subtraction
- Each technique offers different trade-offs between accuracy, computational efficiency, and adaptability
- Selection of an appropriate method depends on the specific requirements of the application and scene characteristics
Frame differencing
- Simple technique comparing each frame with the previous frame or a reference frame
- Calculates absolute difference between corresponding pixels to identify changes
- Effective for detecting fast-moving objects but struggles with slow-moving or stationary foreground elements
- Sensitive to noise and sudden illumination changes
Running Gaussian average
- Models each pixel as a Gaussian distribution with mean and standard deviation
- Updates the model parameters incrementally with each new frame
- Adapts to gradual changes in the background over time
- Computationally efficient but may struggle with multi-modal backgrounds
Mixture of Gaussians
- Represents each pixel with multiple Gaussian distributions to handle multi-modal backgrounds
- Learns and updates the mixture model parameters using expectation-maximization algorithm
- Capable of handling complex backgrounds with multiple states (traffic lights, swaying trees)
- Requires careful parameter tuning to balance adaptability and stability
Kernel density estimation
- Non-parametric approach modeling the background probability density function using kernel functions
- Estimates the likelihood of a pixel belonging to the background based on its recent history
- Adapts well to dynamic backgrounds and gradual changes
- Computationally intensive compared to parametric methods but offers improved accuracy
Foreground detection methods
- Once the background model is established, foreground detection techniques are applied to identify moving objects
- These methods aim to create a binary mask separating foreground from background pixels
- Post-processing steps are often required to refine the initial foreground mask
Thresholding techniques
- Apply a threshold to the difference between the current frame and background model
- Simple and computationally efficient method for foreground segmentation
- Global thresholding uses a single threshold value for the entire image
- Adaptive thresholding adjusts the threshold based on local image characteristics
- Otsu's method automatically determines the optimal threshold by maximizing inter-class variance
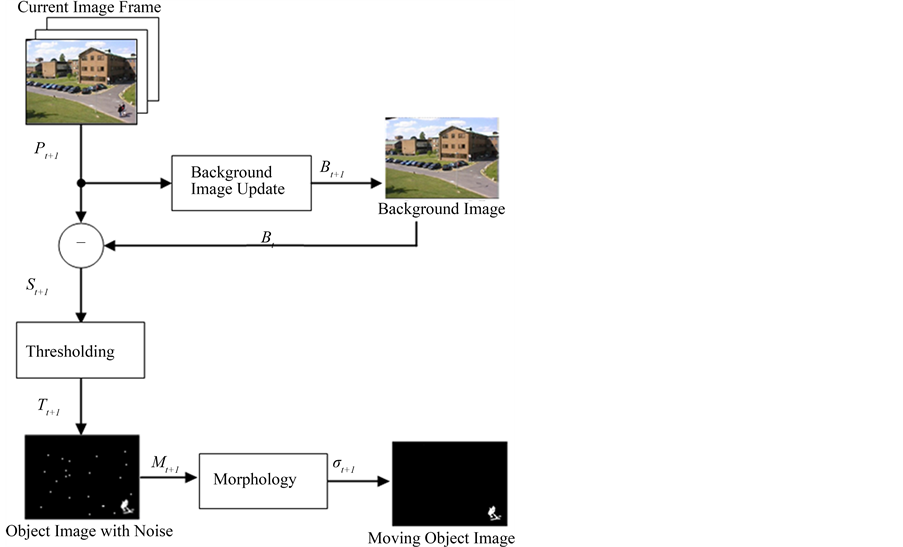
Connected component analysis
- Groups adjacent foreground pixels into connected regions or blobs
- Assigns unique labels to each connected component for further analysis
- Enables filtering of small noise regions and extraction of object properties (size, shape, location)
- Implements efficient algorithms like two-pass labeling or union-find data structures
Morphological operations
- Apply mathematical morphology techniques to refine the foreground mask
- Erosion removes small noise regions and separates connected objects
- Dilation fills small holes and connects nearby regions
- Opening (erosion followed by dilation) removes small objects while preserving larger ones
- Closing (dilation followed by erosion) fills small holes and smooths object boundaries
Performance evaluation metrics
- Quantitative measures used to assess the accuracy and effectiveness of background subtraction algorithms
- Enable objective comparison between different techniques and parameter settings
- Help in selecting the most suitable algorithm for a specific application or dataset
Precision and recall
- Precision measures the proportion of correctly identified foreground pixels among all detected foreground pixels
- Recall (sensitivity) measures the proportion of correctly identified foreground pixels among all actual foreground pixels
- Precision = TP / (TP + FP), where TP = true positives, FP = false positives
- Recall = TP / (TP + FN), where FN = false negatives
- Trade-off exists between precision and recall, often visualized using precision-recall curves
F1 score
- Harmonic mean of precision and recall, providing a single metric to balance both measures
- F1 score = 2 * (Precision * Recall) / (Precision + Recall)
- Ranges from 0 to 1, with 1 indicating perfect precision and recall
- Useful for comparing algorithms when a single performance metric is desired
- Particularly effective when dealing with imbalanced datasets
Intersection over Union (IoU)
- Measures the overlap between the predicted foreground mask and ground truth
- IoU = (Area of Intersection) / (Area of Union)
- Ranges from 0 to 1, with higher values indicating better agreement between prediction and ground truth
- Commonly used in object detection and segmentation tasks
- Provides a spatial measure of accuracy, complementing pixel-wise metrics like precision and recall
Advanced background subtraction algorithms
- State-of-the-art techniques developed to address limitations of traditional methods
- Offer improved performance in challenging scenarios with dynamic backgrounds and varying illumination
- Often combine multiple approaches or incorporate machine learning techniques
ViBe algorithm
- Visual Background Extractor (ViBe) uses a non-parametric pixel-level model
- Maintains a set of background samples for each pixel instead of statistical parameters
- Updates the model randomly to preserve temporal consistency
- Demonstrates fast adaptation to scene changes and robustness to noise
- Requires minimal parameter tuning and achieves real-time performance
Pixel-based adaptive segmenter (PBAS)
- Combines statistical modeling with feedback-based adaptation mechanisms
- Dynamically adjusts decision thresholds and learning rates for each pixel
- Employs a random update strategy to maintain model diversity
- Demonstrates improved performance in scenes with dynamic backgrounds and gradual changes
- Balances adaptability and stability through feedback-driven parameter adjustment
Codebook model
- Represents each pixel with a codebook of codewords encoding background states
- Each codeword contains color and intensity information along with temporal data
- Handles both static and dynamic background elements effectively
- Adapts to cyclic background changes and long-term scene variations
- Compact representation enables efficient memory usage and fast processing
Handling shadows and illumination changes
- Shadows and illumination variations pose significant challenges for background subtraction
- Misclassification of shadows as foreground objects can lead to false detections
- Adaptive techniques are required to maintain accuracy under varying lighting conditions
Shadow detection techniques
- Chromacity-based methods analyze color ratios to distinguish shadows from objects
- Geometry-based approaches exploit spatial relationships and scene geometry
- Texture-based techniques examine local texture patterns to identify shadow regions
- Physical models simulate light-surface interactions to predict shadow characteristics
- Machine learning methods train classifiers to distinguish shadows from genuine foreground objects
Illumination-invariant methods
- Normalize pixel intensities to reduce the impact of global illumination changes
- Employ edge-based features which are less sensitive to lighting variations
- Utilize local binary patterns (LBP) or other texture descriptors robust to illumination changes
- Implement adaptive thresholding techniques to account for local lighting conditions
- Incorporate temporal consistency constraints to filter out sudden illumination changes
Color space transformations
- Convert RGB images to alternative color spaces less sensitive to illumination variations
- HSV (Hue, Saturation, Value) separates color information from intensity
- YCbCr decouples luminance (Y) from chrominance components (Cb, Cr)
- Normalized RGB reduces the impact of intensity changes while preserving color ratios
- Lab color space provides perceptually uniform color representation
Multi-camera background subtraction
- Utilizes multiple cameras to improve coverage and robustness in complex environments
- Enables 3D reconstruction and view-invariant object detection
- Requires additional considerations for camera synchronization and data fusion
Camera synchronization
- Ensures temporal alignment of frames from different cameras
- Hardware-based methods use external triggers or genlock signals
- Software-based approaches employ timestamp matching or feature-based alignment
- Synchronization errors can lead to inconsistencies in multi-view background subtraction
- Sub-frame synchronization techniques address rolling shutter effects in CMOS sensors
View-invariant techniques
- Develop background models that are consistent across multiple camera views
- Employ homography transformations to map between different viewpoints
- Utilize 3D scene reconstruction to create a unified background representation
- Implement occlusion reasoning to handle partially visible objects across views
- Exploit epipolar geometry constraints for consistent foreground detection
Fusion of multiple views
- Combines information from multiple cameras to improve overall detection accuracy
- Voting-based methods aggregate foreground masks from different views
- Probabilistic approaches fuse likelihood maps to generate a consensus foreground
- Occupancy map techniques project detections onto a common ground plane
- Graph-cut algorithms optimize foreground segmentation across multiple views simultaneously
Real-time implementation considerations
- Background subtraction often serves as a preprocessing step for real-time applications
- Balancing accuracy and computational efficiency is crucial for practical deployments
- Various optimization techniques can be employed to achieve real-time performance
Computational efficiency
- Optimize algorithm implementations to reduce computational complexity
- Employ incremental update schemes to avoid unnecessary calculations
- Utilize lookup tables or precomputed values for frequently used operations
- Implement early termination conditions in iterative algorithms
- Apply region of interest (ROI) processing to focus on relevant image areas
Hardware acceleration
- Leverage GPU acceleration for parallel processing of pixel-level operations
- Utilize SIMD (Single Instruction, Multiple Data) instructions for vectorized computations
- Implement FPGA-based solutions for high-speed, low-latency processing
- Explore specialized vision processing units (VPUs) designed for computer vision tasks
- Consider embedded AI accelerators for machine learning-based background subtraction methods
Parallel processing techniques
- Divide image into tiles or blocks for independent processing on multiple cores
- Implement pipeline architectures to overlap different stages of background subtraction
- Utilize task parallelism to distribute workload across multiple processing units
- Employ data parallelism to process multiple frames or camera feeds simultaneously
- Implement load balancing strategies to optimize resource utilization in heterogeneous systems
Post-processing and refinement
- Apply additional processing steps to improve the quality of foreground masks
- Address common issues such as noise, holes, and temporal inconsistencies
- Enhance the overall accuracy and robustness of background subtraction results
Noise reduction techniques
- Apply median filtering to remove salt-and-pepper noise from foreground masks
- Implement bilateral filtering to preserve edges while smoothing homogeneous regions
- Utilize morphological operations (opening, closing) to eliminate small noise regions
- Employ connected component analysis to filter out small, isolated foreground blobs
- Implement temporal filtering techniques to suppress intermittent noise across frames
Hole filling methods
- Apply flood fill algorithms to close interior holes in foreground objects
- Utilize morphological closing operations to bridge small gaps and fill holes
- Implement contour-based techniques to identify and fill concavities in object boundaries
- Employ region growing methods to expand foreground regions into hole areas
- Use inpainting techniques to reconstruct missing foreground information
Temporal consistency
- Implement Kalman filtering to track and predict object positions across frames
- Apply optical flow techniques to estimate motion between consecutive frames
- Utilize temporal median filtering to suppress sporadic false detections
- Implement hysteresis thresholding to maintain object consistency over time
- Employ Markov Random Field (MRF) models to enforce spatio-temporal coherence in foreground masks
Integration with other computer vision tasks
- Background subtraction serves as a foundation for various higher-level computer vision applications
- Effective integration requires consideration of specific requirements and constraints of each task
- Combining background subtraction with other techniques can lead to more robust and versatile systems
Object tracking
- Use foreground masks to initialize object trackers and define regions of interest
- Employ background subtraction to refine object boundaries during tracking
- Integrate motion information from background subtraction to improve prediction models
- Utilize background models to handle occlusions and object reappearance
- Implement feedback mechanisms to update background models based on tracking results
Activity recognition
- Extract motion features from foreground regions for activity classification
- Utilize temporal patterns in foreground masks to identify repetitive actions
- Combine background subtraction with pose estimation for detailed motion analysis
- Implement region-based activity recognition focusing on foreground objects
- Integrate contextual information from background models to improve activity understanding
Scene understanding
- Use background subtraction to identify static and dynamic elements in the scene
- Employ long-term background models to detect and analyze persistent changes
- Integrate foreground object information with semantic segmentation for scene interpretation
- Utilize background subtraction to isolate regions of interest for further analysis (object recognition, anomaly detection)
- Implement multi-layer background models to capture different levels of scene dynamics