Lagrange Multipliers and Lagrangian Function
Lagrange Multiplier and Lagrangian Function
The Lagrange multiplier is a variable we introduce to convert a constrained optimization problem into an unconstrained one. Instead of trying to optimize while separately enforcing a constraint, we fold everything into a single function and optimize that.
The Lagrangian function combines the objective function with the constraint using the multiplier:
Note the sign convention: some textbooks write and others write . Both work because can absorb the sign. Just be consistent with whatever your course uses. The guide below uses the convention, but the worked example keeps the form to match a common presentation. Watch your professor's notes.
Example: Minimize subject to .
Using the convention here:
Critical Points and the Lagrange Multiplier Theorem
To find the critical points of the Lagrangian, set all of its partial derivatives equal to zero:
Condition 3 simply recovers the original constraint . Conditions 1 and 2 enforce the gradient relationship (more on that below). Solving this system simultaneously gives you the critical points .
Lagrange Multiplier Theorem: If is a local extremum of subject to , and , then there exists a scalar such that is a critical point of the Lagrangian. This is a necessary condition, not sufficient on its own.
Continuing the example:
From steps 1 and 2: , so . Substituting into step 3: , giving and .
The single critical point is with , and . Since can grow without bound on the line , this point is the constrained minimum.
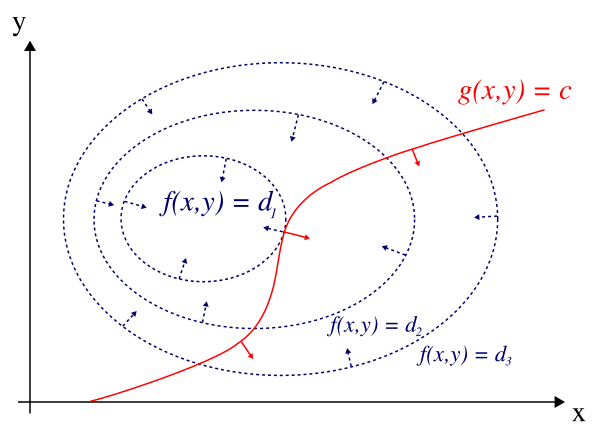
Gradient Vectors and Parallel Gradients
Gradient Vectors and Parallel Gradients
The gradient points perpendicular to the level curves of . Similarly, points perpendicular to the constraint curve .
At a constrained extremum, the level curve of is tangent to the constraint curve. That tangency means the two gradient vectors must be parallel:
This is the geometric heart of the method. If the gradients weren't parallel, you could slide along the constraint and still increase (or decrease) , so you wouldn't be at an extremum.

First-Order Necessary and Second-Order Sufficient Conditions
First-order necessary conditions for to be a constrained extremum:
- (the point lies on the constraint)
- for some scalar
These conditions find candidates but don't tell you whether each candidate is a max, min, or neither.
Second-order sufficient conditions classify those candidates. The standard tool is the bordered Hessian. For one constraint in two variables, the bordered Hessian is:
where all partial derivatives are evaluated at the critical point.
- If , the point is a constrained maximum.
- If , the point is a constrained minimum.
For problems with more variables, you extend the bordered Hessian and check a sequence of determinants (the bordered leading principal minors). Your course may also frame this in terms of the eigenvalues of the Hessian of restricted to the tangent space of the constraint.
Constrained Optimization
Saddle Points and Multiple Constraints
Saddle points are critical points of the Lagrangian that are neither constrained maxima nor constrained minima. At a saddle point, increases in some directions along the constraint surface and decreases in others. The bordered Hessian test is inconclusive (determinant equals zero) or the eigenvalue pattern is mixed.
Multiple Constraints
When you have more than one constraint, introduce a separate multiplier for each. For constraints :
The first-order conditions become:
along with each constraint . An important regularity requirement: the gradient vectors must be linearly independent at the solution. If they aren't, the method can fail.
Example: Minimize subject to and .
Before even differentiating, notice that the two constraints together force and , which gives as the only feasible point. With a single feasible point, there's nothing to optimize over: is both the min and the max on the feasible set. This illustrates that with enough constraints, the feasible set can shrink to a single point (or even be empty).