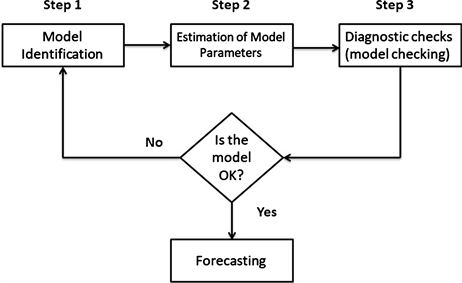
ARIMA models blend autoregressive, differencing, and moving average components to forecast time series data. The Box-Jenkins method offers a step-by-step approach to identify, estimate, and diagnose these models, aiming for simplicity and accuracy in describing stationary data.
Model identification involves examining ACF and PACF plots to determine model order, while avoiding overfitting. Parameter estimation uses maximum likelihood methods to find optimal values. Information criteria like AIC and BIC help select the best model, balancing fit and complexity.
ARIMA Model Identification
Understanding ARIMA Models and Box-Jenkins Methodology
- ARIMA models combine autoregressive (AR), differencing (I), and moving average (MA) components to forecast time series data
- Box-Jenkins methodology provides a systematic approach for identifying, estimating, and diagnosing ARIMA models
- Process involves iterative steps of model identification, parameter estimation, and diagnostic checking
- Aims to find the most parsimonious model that adequately describes the data (balances simplicity and accuracy)
- Requires stationary time series data for effective modeling
- Differencing can be applied to achieve stationarity if necessary
Techniques for Model Identification
- Examine autocorrelation function (ACF) and partial autocorrelation function (PACF) plots to determine model order
- ACF plot helps identify MA order (q)
- PACF plot helps identify AR order (p)
- Use extended autocorrelation function (EACF) for more complex models
- Analyze patterns in ACF and PACF plots to distinguish between AR, MA, and mixed ARMA processes
- AR processes show exponential decay in ACF and sharp cutoff in PACF
- MA processes show sharp cutoff in ACF and exponential decay in PACF
- Consider seasonal patterns and incorporate seasonal ARIMA (SARIMA) models if necessary
- Utilize information criteria (AIC, BIC) to compare different model specifications
Avoiding Overfitting and Applying the Parsimony Principle
- Overfitting occurs when a model is too complex and captures noise in the data rather than underlying patterns
- Parsimony principle advocates for selecting the simplest model that adequately explains the data
- Balance model complexity with goodness of fit to avoid overfitting
- Use cross-validation techniques to assess model performance on out-of-sample data
- Compare nested models using likelihood ratio tests to determine if additional parameters significantly improve fit
- Implement regularization methods (LASSO, Ridge regression) to penalize complex models and prevent overfitting
Parameter Estimation
Maximum Likelihood Estimation for ARIMA Models
- Maximum likelihood estimation (MLE) determines optimal parameter values by maximizing the likelihood function
- Involves finding parameters that make the observed data most probable under the assumed model
- Utilizes numerical optimization algorithms (Newton-Raphson, BFGS) to estimate parameters
- Provides asymptotically unbiased and efficient estimates for large sample sizes
- Handles both stationary and non-stationary ARIMA models effectively
- Allows for the incorporation of exogenous variables in ARIMAX models
Information Criteria for Model Selection
- Information criteria balance model fit against complexity to guide model selection
- Akaike Information Criterion (AIC) measures relative quality of statistical models
- AIC = 2k - 2ln(L), where k is number of parameters and L is maximum likelihood
- Bayesian Information Criterion (BIC) similar to AIC but penalizes complexity more heavily
- BIC = ln(n)k - 2ln(L), where n is sample size
- Lower AIC or BIC values indicate better models, considering both fit and parsimony
- Corrected AIC (AICc) adjusts for small sample sizes and prevents overfitting
- Use these criteria to compare different ARIMA specifications and select optimal model order
Practical Considerations in Parameter Estimation
- Ensure parameter estimates are statistically significant using t-tests or confidence intervals
- Check for parameter redundancy and consider reducing model order if parameters are insignificant
- Examine parameter stability across different subsamples of the data
- Use robust estimation methods for data with outliers or non-Gaussian errors
- Consider Bayesian estimation techniques for incorporating prior knowledge or handling small sample sizes
- Implement bootstrap methods to assess uncertainty in parameter estimates
Model Diagnostics
Comprehensive Residual Analysis
- Residual analysis evaluates model adequacy by examining the difference between observed and fitted values
- Plot residuals over time to check for remaining patterns or trends
- Analyze residual autocorrelation function (ACF) to detect any remaining serial correlation
- Use Ljung-Box test to formally assess residual autocorrelation
- Examine partial autocorrelation function (PACF) of residuals for potential model misspecification
- Create Q-Q plots to assess normality of residuals
- Complement with formal tests (Shapiro-Wilk, Jarque-Bera) for normality
- Check for homoscedasticity using residual versus fitted value plots
- Apply formal tests (White's test, Breusch-Pagan test) for heteroscedasticity
Additional Diagnostic Techniques
- Conduct out-of-sample forecasting to evaluate model performance on new data
- Implement rolling-origin cross-validation for time series to assess forecast accuracy
- Compare model forecasts with naive benchmarks (random walk, seasonal naive)
- Examine forecast error measures (MAE, RMSE, MAPE) for different forecast horizons
- Analyze parameter stability using recursive estimation or rolling window approaches
- Perform sensitivity analysis to assess model robustness to changes in data or assumptions
- Investigate potential structural breaks or regime changes using Chow test or CUSUM plots