Multiple regression analysis expands on simple linear regression by incorporating multiple predictors. It's a powerful tool for understanding complex relationships between variables, allowing us to model real-world scenarios more accurately.
In this section, we'll cover the basics of multiple regression, including model components, interpretation, and evaluation. We'll also dive into significance testing and residual analysis to ensure our models are robust and reliable.
Multiple Regression Fundamentals
Understanding Multiple Regression Components
- Multiple regression analyzes relationships between one dependent variable and two or more independent variables
- Dependent variable represents the outcome or effect being studied in the regression model
- Independent variables act as predictors or explanatory factors influencing the dependent variable
- Ordinary Least Squares (OLS) estimates regression coefficients by minimizing the sum of squared residuals
- Residuals measure the difference between observed and predicted values
- OLS produces unbiased and efficient estimators under certain assumptions
Interpreting Regression Equations
- General form of multiple regression equation:
- Y represents the dependent variable
- X₁, X₂, ..., Xₖ denote independent variables
- β₀ is the y-intercept (value of Y when all X's are zero)
- β₁, β₂, ..., βₖ are regression coefficients indicating the effect of each X on Y
- ε represents the error term capturing unexplained variation
- Partial regression coefficients measure the change in Y for a one-unit increase in X, holding other variables constant
- Standardized coefficients allow comparison of relative importance among independent variables
Evaluating Model Fit
Assessing Overall Model Performance
- Coefficient of determination (R-squared) measures the proportion of variance in Y explained by all X variables collectively
- Ranges from 0 to 1, with higher values indicating better fit
- Calculated as:
- SSE: Sum of Squared Errors
- SST: Total Sum of Squares
- Adjusted R-squared penalizes the addition of irrelevant predictors to the model
- Accounts for the number of independent variables and sample size
- Useful for comparing models with different numbers of predictors
- Standard error of estimate quantifies the average deviation of observed Y values from the regression line
- Smaller values indicate more accurate predictions
- Calculated as:
- Ŷ represents predicted Y values
- n is the sample size
- k is the number of independent variables
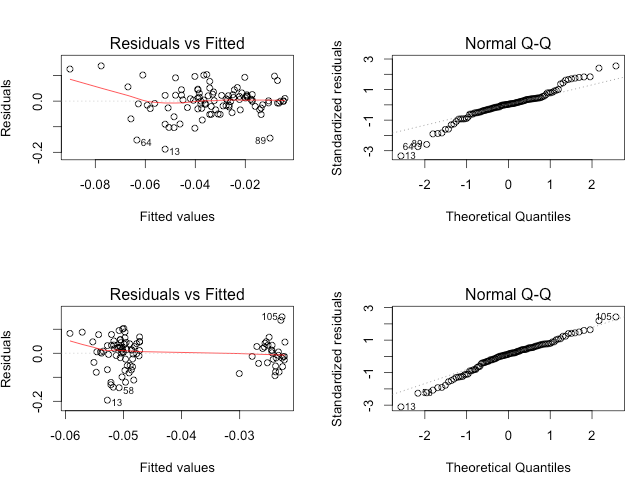
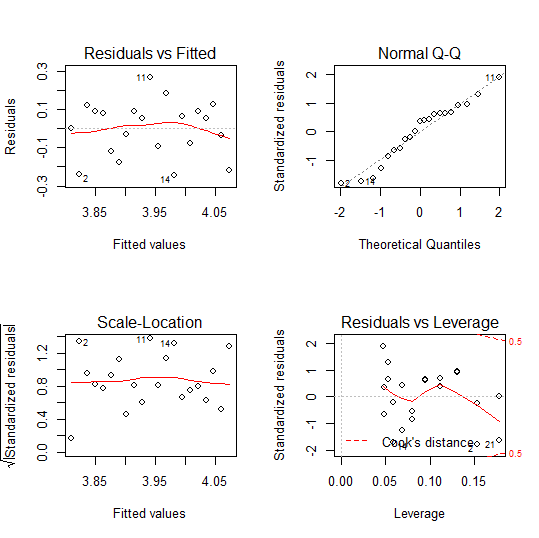
Analyzing Residuals
- Residuals represent the difference between observed and predicted values of the dependent variable
- Plotting residuals helps identify patterns or violations of regression assumptions
- Residual analysis includes examining:
- Normality of residuals (using histograms or Q-Q plots)
- Homoscedasticity (constant variance of residuals)
- Independence of residuals (absence of autocorrelation)
- Outliers and influential observations can be detected through residual analysis
Significance Testing
Assessing Overall Model Significance
- F-statistic tests the overall significance of the regression model
- Null hypothesis: All regression coefficients are simultaneously zero
- Alternative hypothesis: At least one coefficient is non-zero
- F-statistic calculation:
- MSR: Mean Square Regression
- MSE: Mean Square Error
- Large F-values and small p-values indicate a significant overall model
Evaluating Individual Predictor Significance
- T-statistic measures the significance of individual regression coefficients
- Calculated as:
- β_i is the estimated coefficient
- SE(β_i) is the standard error of the coefficient
- Calculated as:
- T-statistic follows a t-distribution with (n - k - 1) degrees of freedom
- P-value represents the probability of obtaining the observed t-statistic under the null hypothesis
- Small p-values (typically < 0.05) indicate statistically significant predictors
- Confidence intervals for coefficients can be constructed using t-statistics and standard errors