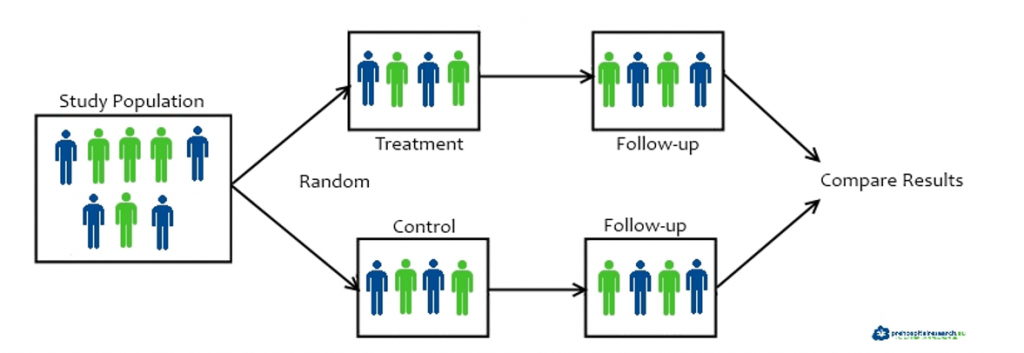
Cluster randomized trials assign groups, not individuals, to treatment conditions. This approach evaluates both direct effects and potential spillovers within groups, making it useful for interventions naturally implemented at the group level like educational programs or community health initiatives.
CRTs differ from individual RCTs in key ways. They typically need larger sample sizes, are less prone to contamination between groups, and require more complex statistical analysis. However, CRTs often better reflect real-world implementation of interventions in natural settings.
Cluster Randomized Trials

more resources to help you study
Definition and Key Features
- Cluster randomized trials (CRTs) assign groups or clusters of individuals to intervention or control conditions
- Clusters serve as the unit of randomization (schools, communities, healthcare facilities)
- CRTs evaluate both direct effects on individuals and potential spillover effects within randomized groups
- Unit of analysis varies between cluster level or individual level based on research question and design
- Particularly useful for interventions naturally implemented at group level (educational programs, community-based interventions)
Applications in Impact Evaluation
- Assess effectiveness of community-based health initiatives (vaccination campaigns)
- Evaluate educational programs implemented across multiple schools (new teaching methods)
- Measure impact of healthcare policies on patient outcomes (hospital-wide infection control measures)
- Study environmental interventions at the neighborhood level (recycling programs)
- Investigate workplace interventions across different company locations (employee wellness programs)
Cluster vs Individual RCTs
Key Differences
- CRTs randomize pre-existing groups while individual RCTs randomize participants individually
- CRTs typically require larger sample sizes to achieve equal statistical power due to clustering effect
- Individual RCTs more prone to contamination between treatment and control groups
- CRTs often have lower implementation costs for group-level interventions
- Statistical analysis in CRTs must account for hierarchical data structure using multilevel modeling
- Ethical considerations in CRTs include cluster-level consent and individual autonomy issues
Practical Implications
- CRTs minimize intervention contamination risk by containing effects within clusters
- Individual RCTs allow for more precise control over individual-level factors
- CRTs facilitate evaluation of interventions that cannot be easily administered at individual level (policy changes)
- Individual RCTs provide more straightforward statistical analysis and interpretation of results
- CRTs often better reflect real-world implementation of interventions in natural settings
- Individual RCTs typically require smaller overall sample sizes for equivalent statistical power
Challenges of Cluster Trials
Design and Implementation Challenges
- Careful cluster selection and definition crucial for representativeness and bias minimization
- Randomization requires special techniques (stratification, restricted randomization) to achieve balance across clusters
- Complex sample size calculations considering both number of clusters and individuals within clusters
- Increased susceptibility to recruitment bias due to knowledge of cluster assignment
- Ethical considerations include obtaining appropriate consent at cluster and individual levels
- Adherence to specific reporting guidelines (CONSORT extension for CRTs) ensures transparency
Analytical Considerations
- Analysis must account for correlation of outcomes within clusters
- Utilize specialized statistical methods (generalized estimating equations, mixed-effects models)
- Potential for unequal cluster sizes complicates analysis and interpretation
- Need to consider both within-cluster and between-cluster variability in outcome measures
- Handling of missing data more complex due to hierarchical structure
- Subgroup analyses require careful consideration of cluster-level and individual-level factors
Intracluster Correlation and Power
Understanding Intracluster Correlation
- Intracluster correlation (ICC) measures similarity of outcomes among individuals within same cluster
- ICC values range from 0 to 1, higher values indicate stronger clustering effect
- Calculated as ratio of between-cluster variance to total variance
- Influences effective sample size through design effect or variance inflation factor
- Design effect calculated as , where m represents average cluster size
- Accurate ICC estimation crucial for proper sample size calculation in CRTs
- ICC estimates derived from pilot studies, previous research, or theoretical considerations
Impact on Sample Size and Power
- Presence of ICC reduces effective sample size in CRTs
- As ICC increases, required sample size for CRT increases to maintain statistical power
- Power in CRTs more sensitive to number of clusters than to cluster size
- Strategies to mitigate ICC impact include increasing number of clusters rather than individuals per cluster
- Consider trade-offs between number of clusters, cluster size, and overall study feasibility
- Use of covariate adjustment can help reduce ICC and improve power
- Conduct sensitivity analyses to assess impact of different ICC values on study conclusions