Big data analytics revolutionizes how we handle vast amounts of information. By collecting, processing, and analyzing massive datasets, organizations can uncover hidden patterns and make data-driven decisions across various fields like business, healthcare, and scientific research.
This topic explores the key characteristics of big data: volume, variety, and velocity. We'll dive into the big data analytics lifecycle, storage systems, processing frameworks, and machine learning applications. Real-world examples and future trends highlight the transformative power of big data analytics.
Overview of big data analytics
- Big data analytics involves collecting, processing, and analyzing large volumes of structured and unstructured data to uncover patterns, correlations, and insights
- Enables organizations to make data-driven decisions, optimize processes, and gain a competitive advantage in various domains such as business, healthcare, and scientific research
- Requires specialized tools, technologies, and frameworks to handle the scale, complexity, and diversity of big data

more resources to help you study
Characteristics of big data
Volume of data
- Refers to the massive scale of data generated and collected from various sources (social media, sensors, transactions)
- Data volumes in the range of terabytes, petabytes, or even exabytes
- Requires scalable storage and processing infrastructure to handle the sheer size of data
Variety of data types
- Big data encompasses structured data (tables, databases), semi-structured data (XML, JSON), and unstructured data (text, images, videos)
- Heterogeneous data formats and sources pose challenges for data integration and analysis
- Necessitates flexible data models and tools to handle diverse data types
Velocity of data generation
- Refers to the speed at which data is generated, collected, and processed
- Real-time data streams from IoT devices, social media, and online transactions require low-latency processing
- Demands efficient data ingestion and analysis pipelines to keep up with the rapid data influx
Big data analytics lifecycle
Data acquisition and ingestion
- Involves collecting data from various sources (databases, APIs, streaming platforms)
- Data ingestion frameworks (Apache Kafka, Apache Flume) enable reliable and scalable data acquisition
- Data is often stored in distributed storage systems (Hadoop Distributed File System) for further processing
Data preparation and processing
- Includes data cleaning, transformation, and integration to ensure data quality and consistency
- Techniques such as data deduplication, data normalization, and data enrichment are applied
- Distributed processing frameworks (Apache Spark, Apache Flink) enable parallel data processing at scale
Data analysis and modeling
- Involves applying statistical, machine learning, and data mining techniques to extract insights and patterns from data
- Includes exploratory data analysis, feature engineering, model training, and evaluation
- Scalable machine learning libraries (MLlib, TensorFlow) enable distributed model training on big data
Data visualization and interpretation
- Presents analysis results in a meaningful and understandable format through visualizations (charts, graphs, dashboards)
- Tools like Tableau, PowerBI, and D3.js facilitate interactive and intuitive data visualization
- Enables stakeholders to explore and derive actionable insights from the analyzed data
Big data storage systems
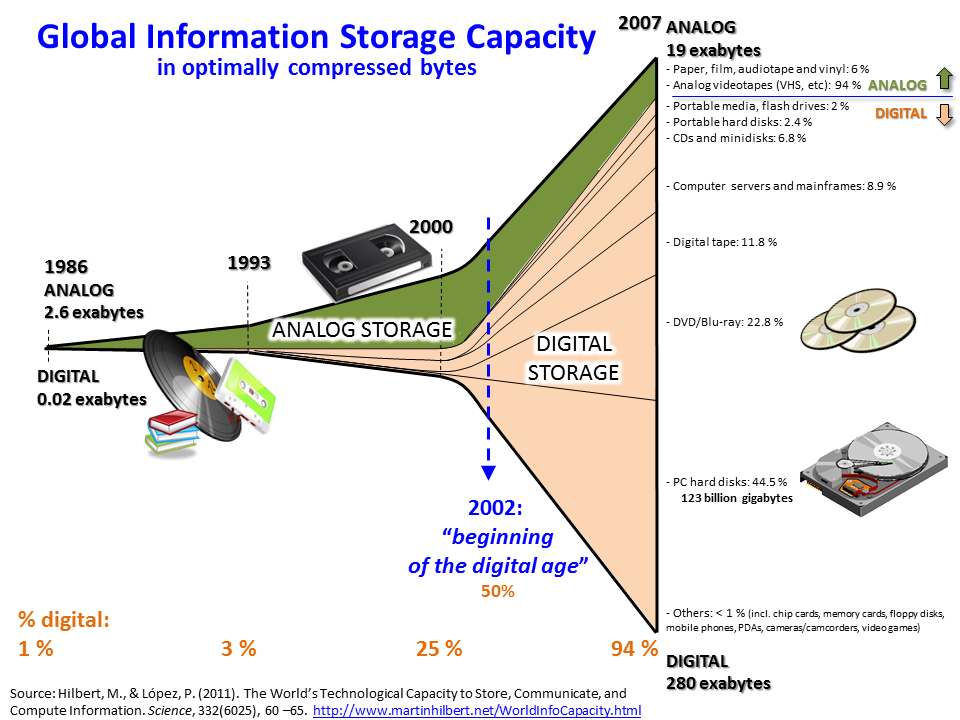
Distributed file systems
- Designed to store and manage large-scale data across a cluster of commodity hardware
- Hadoop Distributed File System (HDFS) is a popular choice for storing big data
- Provides fault tolerance, data replication, and high throughput access to data
NoSQL databases vs relational databases
- NoSQL databases (MongoDB, Cassandra) are designed for scalability, flexibility, and handling unstructured data
- Relational databases (MySQL, PostgreSQL) are based on structured schemas and provide strong consistency guarantees
- NoSQL databases sacrifice some consistency for scalability and are often used in big data scenarios
Big data processing frameworks
Batch processing with Hadoop MapReduce
- Processes large datasets in a distributed manner using the MapReduce programming model
- Divides the data into smaller chunks and processes them in parallel across a cluster of machines
- Suitable for offline, batch-oriented workloads (data aggregation, log analysis)
Stream processing with Apache Spark
- Enables real-time processing of data streams using micro-batch or continuous processing models
- Provides a unified framework for batch processing, stream processing, and machine learning
- Supports high-level APIs in Java, Scala, Python, and R for ease of development
Graph processing with Apache Giraph
- Designed for processing large-scale graph-structured data (social networks, recommendation systems)
- Implements the Bulk Synchronous Parallel (BSP) model for distributed graph algorithms
- Enables iterative graph computations and supports various graph algorithms (PageRank, shortest paths)
Machine learning for big data
Supervised vs unsupervised learning
- Supervised learning involves training models on labeled data to make predictions or classifications
- Unsupervised learning aims to discover patterns and structures in unlabeled data (clustering, dimensionality reduction)
- Big data often requires a combination of both approaches depending on the problem domain and data availability
Scalable machine learning algorithms
- Traditional machine learning algorithms need to be adapted to handle the scale and distributed nature of big data
- Techniques like stochastic gradient descent, mini-batch training, and parameter server architecture enable distributed model training
- Frameworks like Apache Mahout and MLlib provide implementations of scalable machine learning algorithms
Deep learning for big data
- Deep learning models (neural networks) have shown remarkable performance in various domains (computer vision, natural language processing)
- Requires large amounts of labeled data and computational resources for training
- Distributed deep learning frameworks (TensorFlow, PyTorch) enable training deep models on big data using GPU clusters

Real-world applications of big data analytics
Business intelligence and decision making
- Enables data-driven decision making by analyzing customer behavior, market trends, and operational data
- Helps optimize marketing strategies, personalize customer experiences, and improve operational efficiency
- Examples: customer segmentation, demand forecasting, fraud detection
Healthcare and personalized medicine
- Analyzes electronic health records, genomic data, and wearable device data to improve patient outcomes
- Enables early disease detection, personalized treatment plans, and drug discovery
- Examples: precision medicine, clinical decision support, population health management
Social media and sentiment analysis
- Analyzes social media data to understand public opinion, brand perception, and trending topics
- Helps businesses monitor their online presence, engage with customers, and respond to feedback
- Examples: brand monitoring, crisis management, influencer marketing
Internet of Things and sensor data analytics
- Processes and analyzes data generated by connected devices and sensors in real-time
- Enables predictive maintenance, energy optimization, and smart city applications
- Examples: industrial IoT, smart grids, autonomous vehicles
Challenges and future trends in big data analytics
Data privacy and security concerns
- Big data analytics involves handling sensitive and personally identifiable information
- Requires robust data governance, access control, and encryption mechanisms to ensure data privacy and compliance
- Regulations like GDPR and CCPA impose strict requirements on data collection, storage, and processing
Integration of structured and unstructured data
- Big data often involves a mix of structured (databases) and unstructured (text, images) data sources
- Integrating and deriving insights from heterogeneous data types remains a challenge
- Techniques like data lakes and data virtualization aim to provide a unified view of diverse data assets
Real-time analytics and edge computing
- The need for real-time insights and actions is driving the adoption of edge computing paradigms
- Edge computing brings data processing closer to the data sources (IoT devices) to reduce latency and bandwidth requirements
- Enables real-time decision making, autonomous systems, and intelligent applications
Ethical considerations in big data analytics
- Big data analytics raises ethical concerns related to privacy, fairness, and transparency
- Biased or discriminatory outcomes can result from biased data or algorithms
- Ensuring responsible and ethical use of big data requires addressing issues of accountability, explainability, and fairness
- Ethical frameworks and guidelines are needed to guide the development and deployment of big data analytics systems