🥸Advanced Computer Architecture Unit 2 Review
2.4 Performance Analysis of Pipelined Processors
2.4 Performance Analysis of Pipelined Processors
Unit & Topic Study Guides
Intro to Advanced Computer Architecture
Instruction Parallelism and Pipelining
Advanced Pipelining: Techniques & Hazards
Superscalar Design and Dynamic Scheduling
Branch Prediction & Speculative Execution
Out-of-Order Execution & Register Renaming
Memory Hierarchy and Cache Design
Advanced Caching Techniques
Cache Coherence in Multiprocessor Systems
Multicore Architectures & Thread Parallelism
Virtualization Support in Architecture
Processor Power and Energy Management
Reliability and Fault Tolerance in Computing
Performance Analysis & Benchmarking
Security and Trust in Computer Architecture
Quantum and Neuromorphic Computing Trends
Pipelined processors revolutionize CPU performance by breaking instruction execution into stages. This allows multiple instructions to be processed simultaneously, boosting throughput. However, real-world performance gains are limited by factors like data dependencies and branch mispredictions.
Analyzing pipelined processor performance involves metrics like speedup, efficiency, and instructions per cycle (IPC). These help evaluate how well the pipeline is utilized and identify bottlenecks. Techniques like forwarding, branch prediction, and caching are crucial for maximizing pipelined processor performance.
Pipelined Processor Speedup and Efficiency
Theoretical Speedup and Efficiency
- Speedup is the ratio of the execution time of a task on a single processor to the execution time of the same task on a pipelined processor
- Measures the performance improvement achieved by pipelining
- Theoretical speedup assumes ideal conditions with no pipeline stalls or hazards
- Equal to the number of pipeline stages
- In practice, speedup is limited by dependencies, hazards, and other factors
- Efficiency is the ratio of the actual speedup to the theoretical maximum speedup
- Measures how well the pipeline is utilized
- Indicates how close the actual performance is to the ideal performance
Amdahl's Law and Speedup Limitations
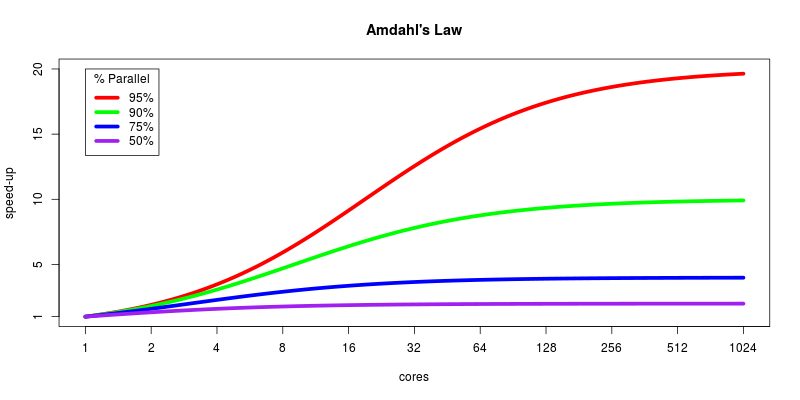
- Amdahl's law states that the overall speedup of a system is limited by the fraction of the workload that cannot be parallelized or pipelined
- Helps determine the maximum achievable speedup
- Example: If 20% of a program's execution time is sequential and cannot be pipelined, the maximum speedup is limited to 5 (1 / 0.2), regardless of the number of pipeline stages
- The sequential portion of the workload limits the overall speedup
- Increasing the number of pipeline stages has diminishing returns on speedup
- Optimizing the sequential portion of the code becomes critical for achieving higher speedup
Pipeline Depth and Width Impact
Pipeline Depth Effects
- Pipeline depth refers to the number of stages in the pipeline
- Increasing pipeline depth can potentially improve performance
- Allows higher clock frequencies
- Enables more overlapping of instruction execution
- Increasing pipeline depth can potentially improve performance
- Deeper pipelines can increase the impact of pipeline hazards and branch mispredictions
- Leads to more pipeline stalls and reduced performance
- The optimal pipeline depth depends on the balance between the increased clock frequency and the pipeline stall overhead
- Example: Increasing the pipeline depth from 5 to 10 stages may allow a higher clock frequency, but the increased impact of hazards and stalls may limit the actual performance gain
Pipeline Width Effects
- Pipeline width refers to the number of parallel pipelines or the number of instructions that can be processed simultaneously in each stage
- Increasing pipeline width can improve performance by exploiting instruction-level parallelism (ILP)
- Wider pipelines require more hardware resources and can increase the complexity of the processor design
- The performance improvement from increasing pipeline width depends on the available ILP in the program and the ability to extract and exploit it
- Example: A processor with a 4-wide pipeline can execute up to 4 instructions per cycle if there are no dependencies or conflicts, potentially achieving a 4x speedup compared to a scalar pipeline
Pipelined Processor Performance Evaluation
Instructions per Cycle (IPC)
- Instructions per cycle (IPC) measures the average number of instructions executed per clock cycle
- Indicates the throughput of the pipeline and the degree of instruction-level parallelism achieved
- The ideal IPC for a pipelined processor is equal to the number of pipeline stages, assuming no stalls or hazards
- In practice, the actual IPC is lower due to pipeline inefficiencies
- Factors affecting IPC include pipeline stalls, data dependencies, branch mispredictions, and memory latency
- Analyzing IPC helps identify performance bottlenecks and optimization opportunities
Cycles per Instruction (CPI)
- Cycles per instruction (CPI) is the reciprocal of IPC
- Represents the average number of clock cycles required to execute an instruction
- A lower CPI indicates better performance
- The overall performance of a pipelined processor can be calculated as the product of the clock frequency and the IPC
- Improving either the clock frequency or the IPC can lead to higher performance
- Example: A processor with a clock frequency of 2 GHz and an IPC of 1.5 would have a performance of 3 billion instructions per second (2 GHz × 1.5 IPC)

Limitations and Solutions for Pipelined Processors
Data Dependencies and Forwarding
- Data dependencies occur when an instruction depends on the result of a previous instruction, causing pipeline stalls
- Solutions include forwarding (bypassing) results between pipeline stages and using out-of-order execution to reorder instructions
- Forwarding allows the result of an instruction to be passed directly to a dependent instruction without waiting for the result to be written back to the register file
- Reduces pipeline stalls caused by data dependencies
- Out-of-order execution allows instructions to be executed in a different order than the program order, based on their dependencies
- Instructions without dependencies can be executed earlier, improving pipeline utilization
Control Dependencies and Branch Prediction
- Control dependencies arise from branch instructions and can cause pipeline stalls due to branch mispredictions
- Branch prediction techniques, such as static or dynamic prediction, and speculative execution can mitigate the impact of control dependencies
- Static branch prediction uses fixed rules or heuristics to predict the outcome of branches
- Examples include always predicting taken or always predicting not taken
- Dynamic branch prediction uses runtime information and history to make more accurate predictions
- Branch prediction buffers (BPBs) or branch target buffers (BTBs) store the history of branch outcomes and target addresses
- Speculative execution allows the pipeline to continue executing instructions based on the predicted branch outcome
- If the prediction is correct, the pipeline continues smoothly
- If the prediction is incorrect, the pipeline is flushed, and execution restarts from the correct path
Structural Hazards and Resource Arbitration
- Structural hazards occur when multiple instructions compete for the same hardware resources, such as memory or functional units
- Solutions include increasing the number of resources, using resource arbitration mechanisms, and employing out-of-order execution
- Increasing the number of resources, such as memory ports or functional units, can reduce resource conflicts
- Example: Providing separate memory ports for instruction fetch and data access can minimize structural hazards
- Resource arbitration mechanisms, such as scoreboarding or reservation stations, manage the allocation and scheduling of shared resources
- Instructions are issued to the appropriate functional units based on resource availability
- Out-of-order execution allows instructions to be executed based on resource availability rather than program order
- Instructions that have their operands ready and resources available can be executed earlier, reducing structural hazards
Memory Latency and Caching
- Memory latency is a significant bottleneck in pipelined processors
- Techniques such as caching, prefetching, and memory hierarchies can help reduce memory access latency and improve performance
- Caching stores frequently accessed data and instructions in fast on-chip memory
- Reduces the average memory access time by exploiting temporal and spatial locality
- Different levels of caches (L1, L2, L3) provide a trade-off between capacity and access speed
- Prefetching techniques predict and fetch data and instructions before they are actually needed
- Hardware prefetchers analyze memory access patterns and speculatively fetch data into the cache
- Software prefetching instructions can be inserted by the compiler to initiate early memory accesses
- Memory hierarchies organize memory into multiple levels with different capacities and access speeds
- Faster memory levels (caches) are closer to the processor, while slower levels (main memory) have larger capacities
- Effective management of the memory hierarchy is crucial for minimizing memory latency and improving performance