📊Actuarial Mathematics Unit 5 Review
5.2 Compound Poisson processes and claim frequency
5.2 Compound Poisson processes and claim frequency
Unit & Topic Study Guides
Probability Theory & Distributions
Stochastic Processes & Time Series
Financial Mathematics and Interest
Life Contingencies & Survival Models
Risk Theory and Insurance Models
Credibility Theory & Experience Rating
Loss Models & Severity Distributions
Ruin Theory & Surplus Processes
Actuarial reserving methods
Pension Math and Retirement Planning
Actuarial Modeling & Statistical Methods
Compound Poisson process fundamentals
A compound Poisson process models the total losses an insurer faces over time by combining two sources of randomness: how often claims arrive and how large each claim is. This separation of frequency and severity is central to how actuaries think about risk.
Definition of compound Poisson process
A compound Poisson process is defined as:
where:
- is a Poisson process with rate that counts the number of claims up to time
- are independent and identically distributed (i.i.d.) random variables representing the severity of each claim
- The are independent of
So tells you how many claims occur, and each tells you how much that claim costs. The process is the running total.
Assumptions and properties
The model rests on several key assumptions:
- Independent increments: The number of events in non-overlapping time intervals are independent.
- Stationary increments: The distribution of the number of events in any interval depends only on the interval's length, not its position in time.
- Independence of severity: Each claim's size is independent of the number of claims and the time at which it occurs.
From these assumptions, you can derive the moments of the aggregate loss directly:
Notice the variance formula uses the second moment , not the variance of . This is a common exam trap. You can also write it as , where and are the mean and variance of the severity distribution.
Differences from standard Poisson process
- In a standard Poisson process, every event contributes exactly 1 to the count. In a compound Poisson process, each event contributes a random amount .
- The standard Poisson process tracks how many events occur. The compound version tracks the total magnitude of those events.
- Because the total is a random sum (random number of random terms), the compound Poisson process has heavier tails and more variability than a simple Poisson count.
Claim frequency modeling
Claim frequency modeling focuses on predicting how many claims will occur in a given period. Getting this right is essential for setting premiums, holding adequate reserves, and managing portfolio risk. The choice of frequency distribution depends on the data's characteristics, particularly the relationship between the mean and variance.
Claim frequency vs claim severity
- Claim frequency is the count of claims in a time period (e.g., 12 auto claims per month).
- Claim severity is the dollar amount of each individual claim (e.g., a single claim costing $5,000).
Modeling these separately gives actuaries more flexibility. You can change the severity assumption without rebuilding the frequency model, and vice versa. The compound Poisson process then combines both into an aggregate loss model.
Poisson distribution for claim frequency
The Poisson distribution is the default starting point for claim frequency. Its probability mass function with rate parameter is:
A defining feature of the Poisson distribution is that its mean and variance are both equal to . This property, called equidispersion, makes estimation straightforward: the sample mean is a sufficient estimator for .
The Poisson works well when claims are rare, independent events. But real insurance data often shows overdispersion (variance exceeding the mean), which signals that the Poisson assumption may be too restrictive.
Negative binomial distribution for claim frequency
When overdispersion is present, the negative binomial distribution is a natural alternative. Its PMF with parameters and is:
The negative binomial has a useful interpretation: it arises as a Poisson-gamma mixture. That is, if the Poisson rate itself varies across policyholders according to a gamma distribution, the resulting marginal distribution of claim counts is negative binomial. This captures unobserved heterogeneity in the portfolio, where some policyholders are inherently riskier than others.
Because it has two parameters, the negative binomial can fit data where the variance is substantially larger than the mean.
Other distributions for modeling claim frequency
Depending on the data, other distributions may be appropriate:
- Binomial: Useful when there's a fixed maximum number of possible claims (e.g., a policy covering exactly 3 items).
- Geometric: A special case of the negative binomial with .
- Zero-inflated Poisson: Handles excess zeros from a population where some policyholders have zero probability of claiming.
The choice should be guided by goodness-of-fit tests (chi-squared, likelihood ratio) and the balance between model complexity and interpretability. A more complex distribution isn't always better if it doesn't meaningfully improve the fit.
Compound Poisson process applications
Compound Poisson processes are workhorses across actuarial practice. They appear in pricing, reserving, and solvency analysis for property and casualty, health, and life insurance.
Aggregate loss models
An aggregate loss model describes the total losses for an insurance portfolio over a fixed period. The structure is:
where and each follows a severity distribution (e.g., lognormal, gamma, or Pareto).
Actuaries use aggregate loss models to:
- Estimate the full distribution of total losses, not just the mean
- Calculate risk measures like Value-at-Risk (VaR) and Expected Shortfall (ES)
- Determine premiums and required reserves
Since the exact distribution of is rarely available in closed form, actuaries typically rely on recursive methods (Panjer's recursion), numerical convolution, or simulation.
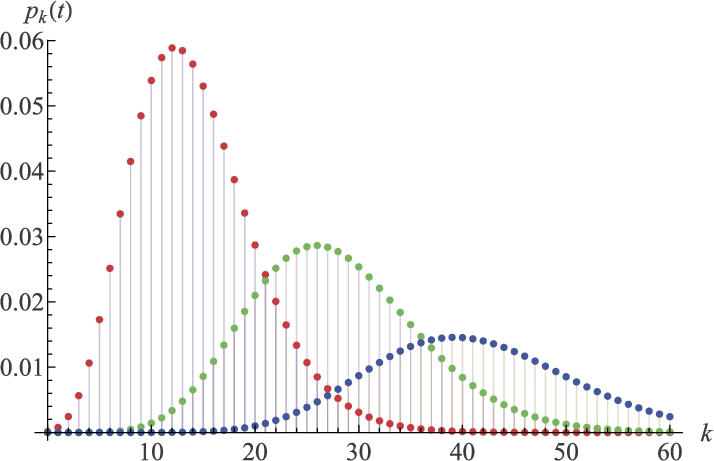
Collective risk models
Collective risk models build on aggregate loss models by incorporating policy features that modify the insurer's actual exposure:
- Deductibles reduce each claim by a fixed amount
- Policy limits cap the insurer's liability per claim
- Reinsurance transfers a portion of losses to another party
These modifications change the effective severity distribution. For example, with a deductible , the insurer pays per claim, and some claims produce zero payment. Collective risk models help actuaries optimize contract design and evaluate risk-sharing arrangements.
Ruin theory and surplus process
Ruin theory studies whether an insurer's surplus will ever drop below zero. The surplus process is:
where is the initial capital, is the premium income rate per unit time, and is the compound Poisson aggregate loss process.
Ruin occurs if for some . The probability of ruin depends on the initial capital, the premium loading, and the claim distribution. Actuaries use ruin theory to determine how much initial capital is needed and what safety loading to include in premiums to keep the ruin probability acceptably low.
Parameter estimation for compound Poisson processes
To use a compound Poisson model in practice, you need to estimate the Poisson rate and the parameters of the severity distribution from data. Three main approaches are used.
Method of moments
The method of moments matches theoretical moments to sample moments. For a compound Poisson process observed over time :
- Compute the sample mean and sample variance of the aggregate losses.
- Set and .
- Solve these equations (along with any additional moment equations if the severity distribution has more parameters) for , , and .
This method is simple and gives closed-form solutions, but it can be inefficient (high variance estimates) compared to other methods, especially with small samples.
Maximum likelihood estimation
Maximum likelihood estimation (MLE) finds the parameter values that maximize the probability of observing the data you actually have.
For a compound Poisson process, the likelihood function combines:
- The Poisson PMF for the observed claim counts
- The severity density for the observed claim amounts
MLE is generally more efficient than method of moments, but the likelihood for aggregate losses can be complex. Numerical optimization techniques like the EM algorithm or gradient-based methods are typically required. MLE also provides standard errors and confidence intervals through the Fisher information matrix.
Bayesian estimation techniques
Bayesian estimation starts with a prior distribution reflecting existing beliefs about the parameters, then updates it with observed data to produce a posterior distribution.
This approach is especially valuable when:
- Historical data is limited
- Expert judgment needs to be formally incorporated
- You want a full distribution of parameter uncertainty, not just point estimates
Computation usually requires Markov chain Monte Carlo (MCMC) methods such as the Gibbs sampler or Metropolis-Hastings algorithm, since posterior distributions for compound Poisson models rarely have closed forms.
Simulation of compound Poisson processes
Simulation lets actuaries generate synthetic claim data to study scenarios that historical data alone can't cover. This is particularly useful for estimating tail risk measures and stress-testing models.
Simulation algorithms and techniques
The basic algorithm for simulating a compound Poisson process over a period :
- Generate to get the number of claims.
- For each claim , generate from the severity distribution.
- Compute the aggregate loss: .
To generate severity variates, common techniques include:
- Inverse transform sampling: Apply the inverse CDF to a uniform random variable. Works well when the inverse CDF has a closed form.
- Acceptance-rejection methods: Useful for distributions where the inverse CDF is not tractable.
Variance reduction techniques like antithetic variates or control variates can reduce the number of simulation runs needed for a given level of accuracy.
Monte Carlo methods
Monte Carlo estimation works by repeating the simulation algorithm many times (e.g., 10,000 or 100,000 runs) and using the empirical distribution of results to estimate quantities of interest.
For example, to estimate the 99.5th percentile VaR of aggregate losses:
- Simulate a large number of times.
- Sort the results.
- The 99.5th percentile of the simulated values estimates the VaR.
Accuracy improves with more runs, but convergence is slow (error decreases proportionally to ). Advanced techniques like importance sampling and stratified sampling can accelerate convergence, especially for rare-event probabilities.
Applications of simulated compound Poisson processes
- Pricing: Test how premiums change under different assumptions about or the severity parameters.
- Reserving: Estimate the distribution of future claim payments, including IBNR (incurred but not reported) claims, and assess reserve adequacy.
- Risk management: Evaluate the effectiveness of reinsurance arrangements, deductibles, or policy limits by simulating losses with and without these features.
- Stress testing: Explore extreme scenarios (e.g., doubling the claim rate) that may not appear in historical data.

Modifications to compound Poisson processes
The basic compound Poisson model makes strong assumptions. When real data violates those assumptions, several modifications can bring the model closer to reality.
Zero-inflated compound Poisson processes
Some portfolios have more zero-claim observations than a Poisson distribution predicts. This happens when a portion of policyholders have essentially no exposure to the risk. A zero-inflated model handles this by mixing a point mass at zero with a standard Poisson:
Here is the probability that a policyholder belongs to the "structural zero" group (they'll never claim), and is the probability they follow a standard Poisson process. The parameter is estimated alongside .
Marked compound Poisson processes
A marked compound Poisson process attaches a random mark to each event, carrying additional information beyond just the claim amount. Marks might represent:
- The type of claim (e.g., bodily injury vs. property damage)
- The geographic location of the loss
- The line of business affected
The marks are assumed i.i.d. and can have distributions that depend on the event time. This extension is useful for modeling multi-line portfolios where different claim types have different severity distributions.
Non-homogeneous compound Poisson processes
In the standard model, the rate is constant over time. A non-homogeneous compound Poisson process replaces this with a time-varying rate function . The expected number of claims in becomes:
The rate function can be specified parametrically (e.g., for a linear trend, or for exponential growth) or estimated non-parametrically from data. This modification captures seasonal patterns, long-term trends, or shifts in the underlying risk environment.
Generalizations of compound Poisson processes
Beyond simple modifications, compound Poisson processes can be generalized to handle more complex dependence structures and heterogeneity.
Compound mixed Poisson processes
A compound mixed Poisson process treats the Poisson rate as a random variable drawn from a mixing distribution. This adds a layer of randomness that captures unobserved heterogeneity across the portfolio.
Common mixing distributions and the resulting claim count distributions:
| Mixing Distribution | Resulting Count Distribution |
|---|---|
| Gamma | Negative binomial |
| Inverse Gaussian | Poisson-inverse Gaussian |
| Log-normal | Poisson-log-normal |
The mixed Poisson framework is particularly useful when different risk classes exist in the portfolio but aren't fully captured by observable rating factors.
Compound Cox processes
A compound Cox process (also called a doubly stochastic compound Poisson process) goes further than the non-homogeneous model by making the rate function itself a stochastic process.
The rate process might follow a Brownian motion, an Ornstein-Uhlenbeck process, or a jump-diffusion model. This captures situations where claim frequency is driven by external random factors, such as economic cycles, weather patterns, or evolving regulatory environments. The randomness in the rate creates additional variability and heavier tails in the aggregate loss distribution.
Compound renewal processes
A compound renewal process replaces the Poisson arrival process with a general renewal process, where inter-arrival times between claims are i.i.d. but not necessarily exponential.
Possible inter-arrival distributions include Erlang, Weibull, or Pareto. This generalization accommodates:
- Clustering: Claims that tend to arrive in bursts (inter-arrival times shorter than exponential would predict)
- Regularity: Claims that arrive more regularly than a Poisson process suggests
- Heavy-tailed waiting times: Long quiet periods followed by sudden activity
The trade-off is analytical tractability. Many of the clean formulas available for the Poisson case no longer hold, and simulation becomes more important.
Compound Poisson processes in actuarial applications
Pricing insurance policies
The compound Poisson process provides the foundation for calculating the pure premium (the expected loss per policy):
The actual charged premium adds a safety loading to cover variability and ensure profitability. Actuaries use the full aggregate loss distribution from the compound Poisson model to assess how much loading is appropriate, often targeting a specific probability of the premium being sufficient (e.g., 95% or 99%).
Calculating risk measures and premiums
Two key risk measures derived from compound Poisson models:
- Value-at-Risk (VaR): The loss level exceeded with probability (e.g., VaR at 99.5% is the loss exceeded only 0.5% of the time).
- Expected Shortfall (ES): The expected loss given that the loss exceeds the VaR. ES captures the severity of tail events better than VaR alone.
Premium principles based on compound Poisson models include:
- Expected value principle: , where is the safety loading factor
- Standard deviation principle:
- Variance principle:
Each principle reflects a different attitude toward risk, and the compound Poisson model provides the moments needed for all of them.
Reserving and loss prediction
Reserving means setting aside funds for:
- IBNR (Incurred But Not Reported): Claims that have happened but haven't been filed yet
- RBNS (Reported But Not Settled): Claims filed but not yet fully paid
Compound Poisson processes model the development of claims over time, helping actuaries estimate the distribution of future payments rather than just a single point estimate. This distributional information is critical for assessing whether reserves are adequate at a given confidence level.
For loss prediction, compound Poisson models can be combined with time series methods and machine learning to forecast future claim activity. The compound Poisson structure provides a principled probabilistic framework, while data-driven techniques can improve the estimation of the rate and severity parameters as new information arrives.