📊Actuarial Mathematics Unit 1 Review
1.8 Moment generating functions and transformations
1.8 Moment generating functions and transformations
Unit & Topic Study Guides
Probability Theory & Distributions
Stochastic Processes & Time Series
Financial Mathematics and Interest
Life Contingencies & Survival Models
Risk Theory and Insurance Models
Credibility Theory & Experience Rating
Loss Models & Severity Distributions
Ruin Theory & Surplus Processes
Actuarial reserving methods
Pension Math and Retirement Planning
Actuarial Modeling & Statistical Methods
Definition of moment generating functions
The moment generating function (MGF) of a random variable uniquely characterizes its probability distribution. If two random variables share the same MGF, they follow the same distribution. This makes MGFs one of the most useful identification tools in actuarial probability.
The MGF of a random variable is defined as:
where is a real number. For a continuous random variable, this expands to , and for a discrete random variable, .
The MGF exists if is finite for all in some open interval around zero (i.e., for where ).
Laplace transforms
Laplace transforms are closely related to MGFs. The Laplace transform of a function is defined as:
where is a complex number. Notice the structural similarity: for a non-negative random variable with density , the MGF evaluated at equals the Laplace transform of the density. Laplace transforms appear in actuarial work when solving differential equations in ruin theory and analyzing aggregate claim distributions.
Existence of MGFs
Not every distribution has an MGF. For the MGF to exist, must be finite in a neighborhood of . Distributions with heavy tails can violate this condition.
- The Cauchy distribution has no MGF because is infinite for every .
- The lognormal distribution also lacks an MGF, despite having finite moments of all orders.
- When an MGF doesn't exist, you can use the characteristic function instead (covered at the end of this guide).
Properties of moment generating functions
MGFs have several properties that make distribution analysis much more tractable, especially when working with sums of independent random variables.
Uniqueness property
If two random variables and have MGFs that are equal in a neighborhood of zero, i.e., for all , then and have the same distribution.
This is the property you'll use most often on exam problems: compute an MGF, recognize it as belonging to a known distribution, and conclude the random variable follows that distribution.
MGF of linear transformations
For a linear transformation , the MGF is:
This follows directly from the definition. The constant contributes a factor of , while the scaling constant replaces with in the original MGF.
MGF of linear combination of independent random variables
If and are independent random variables, then for :
Independence is critical here. Without it, you can't factor the joint expectation into the product of individual expectations. This extends naturally to independent random variables:
Moments and moment generating functions
The name "moment generating function" comes from the fact that you can extract every moment of a distribution by differentiating the MGF.
Relationship between moments and MGFs
The -th moment of is obtained by taking the -th derivative of the MGF and evaluating at :
Why does this work? Expand as a Taylor series:
Each coefficient of contains , so differentiating times and setting isolates .
Deriving moments from MGFs
Here's the step-by-step process:
-
Write down the MGF .
-
Differentiate with respect to once. Evaluate at to get the mean: .
-
Differentiate again. Evaluate at to get the second raw moment: .
-
Compute the variance using .
-
Continue differentiating for higher moments as needed.
Central moments vs raw moments
- Raw moments are computed about the origin:
- Central moments are computed about the mean:
The first central moment is always zero. The second central moment is the variance. The third and fourth central moments (often standardized) give skewness and kurtosis, which describe the asymmetry and tail weight of the distribution.
You can convert between raw and central moments. For example, the variance equals the second raw moment minus the square of the first: .
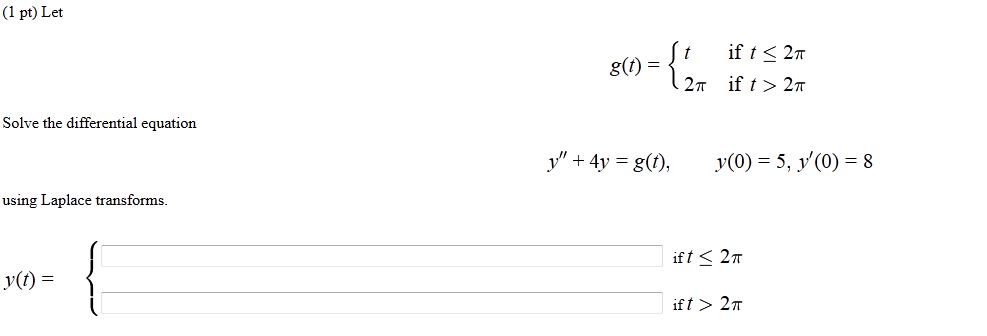
Transformations using moment generating functions
MGFs are especially handy for finding the distribution of sums and differences of independent random variables, since multiplication of MGFs is much simpler than convolving densities.
MGF of sum of independent random variables
If and are independent:
This is the special case of the linear combination formula with . It extends to any finite number of independent summands:
This property is what makes MGFs so powerful for proving closure properties (e.g., the sum of independent normals is normal, the sum of independent Poissons is Poisson).
MGF of difference of random variables
For independent and , write . The MGF of is , so:
MGF of product of independent random variables
There is no general product rule analogous to the sum rule. The MGF of cannot typically be expressed in terms of and alone. For products, you usually need to work directly from the definition or use other techniques (such as the distribution of the product derived from the joint density).
Applications of moment generating functions
Determining distributions from MGFs
The standard exam technique:
- Compute the MGF of the random variable in question (often a sum of independent random variables).
- Simplify the expression.
- Compare the result to the table of known MGFs.
- By the uniqueness property, identify the distribution.
Example: Suppose are i.i.d. Exponential with rate . The MGF of each is . The MGF of the sum is:
This is the MGF of a Gamma distribution with shape and rate . So .
Deriving probability distributions
You can recover a PDF or PMF from an MGF by expanding it as a Taylor series around and reading off the moments, then matching to a known distribution family. In practice, direct recognition (as above) is far more common on exams than full inversion.
Calculating probabilities using MGFs
MGFs are not typically used to compute individual probabilities like directly. For that, you'd use the CDF. However, once you've identified the distribution via its MGF, you can use the known CDF or probability tables for that distribution to find probabilities.
Common moment generating functions
The following table summarizes MGFs you should have memorized:
| Distribution | Parameters | MGF | Domain of |
|---|---|---|---|
| Bernoulli | all | ||
| Binomial | all | ||
| Poisson | all | ||
| Geometric | |||
| Exponential | |||
| Gamma | |||
| Normal | all |
MGF of normal distribution
This exists for all real . For the standard normal (), it simplifies to . You can verify: and .
MGF of exponential distribution
The restriction is important. Differentiating: , so . Differentiating again gives , so .
MGF of gamma distribution
Note that the exponential distribution is the special case . The mean is and the variance is .
MGF of binomial distribution
This exists for all . Differentiating and evaluating at : and . You can also use this MGF to prove that the sum of independent Bernoulli random variables is binomial, since the MGF of a single Bernoulli trial is , and multiplying of these gives the binomial MGF.
Limitations of moment generating functions
Non-existence of MGFs for certain distributions
The main limitation: some distributions simply don't have an MGF. Heavy-tailed distributions like the Cauchy and lognormal are the classic examples. If you encounter a distribution where for all , the MGF approach won't work, and you'll need to use characteristic functions instead.
Convergence issues with MGFs
Even when an MGF exists, it may only converge on a restricted interval around zero (e.g., for the exponential). This can limit its usefulness in certain theoretical arguments. The characteristic function avoids this problem entirely because for all , guaranteeing convergence.
Characteristic functions vs moment generating functions
Definition of characteristic functions
The characteristic function of a random variable replaces the real exponential in the MGF with a complex exponential:
where and is real. For continuous random variables: . This is the Fourier transform of the density.
Properties of characteristic functions
Characteristic functions share the key properties of MGFs:
- Uniqueness: for all implies and have the same distribution.
- Independence and sums: If and are independent, .
- Moment extraction: , provided the -th moment exists.
Advantages of characteristic functions over MGFs
The characteristic function always exists for any random variable, because ensures the expectation is bounded. This is the decisive advantage over MGFs.
Characteristic functions are the standard tool for proving the Central Limit Theorem: you show that the characteristic function of the standardized sum converges to (the characteristic function of the standard normal), then invoke the continuity theorem.
The tradeoff is that characteristic functions involve complex arithmetic, which makes direct computation less convenient than MGFs when the MGF exists. For exam purposes, use MGFs whenever they exist. Reserve characteristic functions for distributions where MGFs fail or for theoretical proofs requiring universal applicability.